Нейронні мережі: приклад, визначення, значення, сфера застосування
Штучний інтелект та нейроні мережі являють собою неймовірно захоплюючі і потужні методи, засновані на машинному навчанні, які використовуються для вирішення багатьох реальних задач. Найпростіший приклад нейронної мережі - вивчення пунктуації та граматики для автоматичного створення абсолютно нового тексту з виконанням всіх правил орфографії.
 Їх робота, як і багатьох інших вчених, не призначалася для точного опису роботи біологічного мозку. Штучна нейронна мережа була розроблена як обчислювальна модель, що працює за принципом функціонування мозку для вирішення широкого кола завдань. Очевидно, що є вправи, які просто вирішити для комп'ютера, але важко для людини, наприклад, витяг квадратного кореня з десятизначного числа. Цей приклад нейронна мережа обчислить менш ніж за мілісекунду, а людині потрібні хвилини. З іншого боку, є такі, які неймовірно просто вирішити людині, але не під силу комп'ютера, наприклад, вибрати фон зображення.
Їх робота, як і багатьох інших вчених, не призначалася для точного опису роботи біологічного мозку. Штучна нейронна мережа була розроблена як обчислювальна модель, що працює за принципом функціонування мозку для вирішення широкого кола завдань. Очевидно, що є вправи, які просто вирішити для комп'ютера, але важко для людини, наприклад, витяг квадратного кореня з десятизначного числа. Цей приклад нейронна мережа обчислить менш ніж за мілісекунду, а людині потрібні хвилини. З іншого боку, є такі, які неймовірно просто вирішити людині, але не під силу комп'ютера, наприклад, вибрати фон зображення.  Вчені витратили масу часу, досліджуючи і упроваджуючи складні рішення. Найбільш поширений приклад нейронної мережі в обчислювальній техніці - розпізнавання образів. Область застосування варіюється від оптичного розпізнавання символів і фото, надрукованих чи рукописних сканів у цифровий текст до розпізнавання осіб.
Вчені витратили масу часу, досліджуючи і упроваджуючи складні рішення. Найбільш поширений приклад нейронної мережі в обчислювальній техніці - розпізнавання образів. Область застосування варіюється від оптичного розпізнавання символів і фото, надрукованих чи рукописних сканів у цифровий текст до розпізнавання осіб.
 Людський мозок є виключно складною і найпотужнішою з відомих обчислювальних машин. Внутрішня робота його моделюється навколо концепції нейронів і їх мереж, відомих як біологічні нейронні мережі. Мозок містить близько 100 мільярдів нейронів, які пов'язані цими мережами. На високому рівні вони взаємодіють один з одним через інтерфейс, що складається з терміналів аксонів, пов'язаних з дендритами через проміжок - синапс. Говорячи простою мовою, один передає повідомлення іншому через цей інтерфейс, якщо сума зважених вхідних сигналів від одного або декількох нейронів перевищує поріг, щоб викликати передачу. Це називається активацією, коли поріг перевищено, а повідомлення передається наступного нейрона. Процес підсумовування може бути математично складним. Вхідний сигнал являє собою зважену комбінацію таких сигналів, а зважування кожного означає, що цей вхід може по-різному впливати на подальші обчислення і на кінцевий вихід мережі.
Людський мозок є виключно складною і найпотужнішою з відомих обчислювальних машин. Внутрішня робота його моделюється навколо концепції нейронів і їх мереж, відомих як біологічні нейронні мережі. Мозок містить близько 100 мільярдів нейронів, які пов'язані цими мережами. На високому рівні вони взаємодіють один з одним через інтерфейс, що складається з терміналів аксонів, пов'язаних з дендритами через проміжок - синапс. Говорячи простою мовою, один передає повідомлення іншому через цей інтерфейс, якщо сума зважених вхідних сигналів від одного або декількох нейронів перевищує поріг, щоб викликати передачу. Це називається активацією, коли поріг перевищено, а повідомлення передається наступного нейрона. Процес підсумовування може бути математично складним. Вхідний сигнал являє собою зважену комбінацію таких сигналів, а зважування кожного означає, що цей вхід може по-різному впливати на подальші обчислення і на кінцевий вихід мережі.
Мережі з глибоким навчанням відрізняються від поширених нейронних з одним прихованим шаром. Приклад навчання нейронних мереж – мережі Кохонена.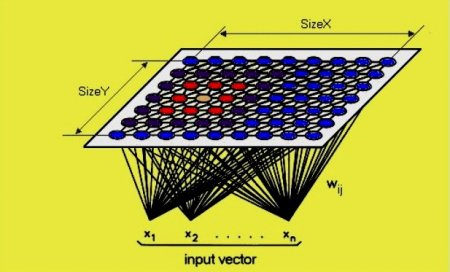 У мережах з глибоким навчанням кожен шар пізнає заданий набір функцій на основі вихідної інформації попереднього рівня. Чим далі просуватися в нейронну мережу, тим складніше об'єкти, які можуть розпізнаватися вузлами, оскільки вони об'єднують і рекомбінують об'єкти з попереднього рівня. Мережі глибокого навчання виконують автоматичне витяг функцій без участі людини, на відміну від більшості традиційних алгоритмів і закінчуються вихідним рівнем: логічним або softmax-класифікатором, який присвоює ймовірність конкретного результату і називається прогнозом.
У мережах з глибоким навчанням кожен шар пізнає заданий набір функцій на основі вихідної інформації попереднього рівня. Чим далі просуватися в нейронну мережу, тим складніше об'єкти, які можуть розпізнаватися вузлами, оскільки вони об'єднують і рекомбінують об'єкти з попереднього рівня. Мережі глибокого навчання виконують автоматичне витяг функцій без участі людини, на відміну від більшості традиційних алгоритмів і закінчуються вихідним рівнем: логічним або softmax-класифікатором, який присвоює ймовірність конкретного результату і називається прогнозом. 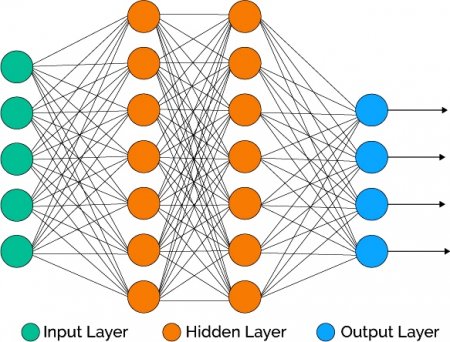 Простий приклад нейронної мережі - архітектурно штучна нейронна ANN-мережу, де: Input layer - вхідний шар. Hidden layer - прихований шар. Output layer - вихідний шар. Вона моделюється з використанням шарів штучних нейронів або обчислювальних одиниць, здатних приймати вхідні дані та використовувати функцію активації разом з пороговим значенням, щоб визначити, передаються чи повідомлення.
Простий приклад нейронної мережі - архітектурно штучна нейронна ANN-мережу, де: Input layer - вхідний шар. Hidden layer - прихований шар. Output layer - вихідний шар. Вона моделюється з використанням шарів штучних нейронів або обчислювальних одиниць, здатних приймати вхідні дані та використовувати функцію активації разом з пороговим значенням, щоб визначити, передаються чи повідомлення.
У простій моделі перший шар - це вхідний, за яким слід прихований і, нарешті, вихідний. Кожен може містити один або декілька нейронів. Моделі можуть ставати все більш складними зі збільшенням можливостей абстракції і рішення проблем, кількості прихованих шарів, числа нейронів в кожному даному шарі і кількості колій між ними. Архітектура і налаштування моделі є основними компонентами методів ANN в доповнення до самих алгоритмів навчання. Вони є надзвичайно потужними і вважаються алгоритмами чорного ящика, що означає, що їх внутрішню роботу дуже важко зрозуміти і пояснити. Традиційно на вченого або програміста даних лягає відповідальність виконання процесу вилучення ознак у більшості інших підходів машинного навчання поряд з вибором функцій і проектуванням.
Традиційно на вченого або програміста даних лягає відповідальність виконання процесу вилучення ознак у більшості інших підходів машинного навчання поряд з вибором функцій і проектуванням.
 Докладне обговорення безлічі різних архітектур моделей і алгоритмів такого роду навчання дуже просторове і суперечливе. Найбільш вивченими вважаються: Прямі нейронні мережі. Рецидивуюча нейронна мережа. Багатошарові персептрони (MLP). Згорткові нейронні мережі. Рекурсивні нейронні мережі. Глибокі мережі переконань. Згорткові мережі глибоких переконань. Самоорганізуються карти. Глибокі машини Больцмана. Складені шумоподавляющіе авто-кодери.
Докладне обговорення безлічі різних архітектур моделей і алгоритмів такого роду навчання дуже просторове і суперечливе. Найбільш вивченими вважаються: Прямі нейронні мережі. Рецидивуюча нейронна мережа. Багатошарові персептрони (MLP). Згорткові нейронні мережі. Рекурсивні нейронні мережі. Глибокі мережі переконань. Згорткові мережі глибоких переконань. Самоорганізуються карти. Глибокі машини Больцмана. Складені шумоподавляющіе авто-кодери.
Рекурентні нейронні мережі RNN перетворюють вхідну послідовність у вихідну, яка знаходиться в іншій області, наприклад, змінює послідовність звукових тисків в послідовність ідентифікаторів слів. Джон Хопфілд представив Hopfield Net у статті 1982 року «Нейронні мережі та фізичні системи з виникаючими колективними обчислювальними можливостями». У мережі Хопфілда (HN) кожен нейрон зв'язаний з будь-яким іншим. Вони навчаються шляхом встановлення їх значення на бажану схему, після чого можна обчислити вагові коефіцієнти.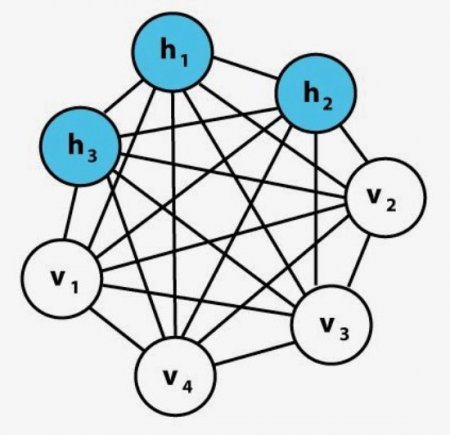 Машина Больцмана являє собою тип стохастичної рекурентної нейронної мережі, яку можна розглядати як аналог мереж Хопфілда. Це був один з перших варіантів, які вивчають внутрішні уявлення, які вирішують складні комбінаторні задачі. Вхідні нейрони стають вихідними в кінці повного оновлення. Генеративна змагальна мережа Яна Гудфеллоу (GAN) складається з двох мереж. Часто це комбінація Feed Forwards і Convolutional Neural Nets. Одна генерує контент генеративний, а інша повинна оцінювати контент дискримінаційний.
Машина Больцмана являє собою тип стохастичної рекурентної нейронної мережі, яку можна розглядати як аналог мереж Хопфілда. Це був один з перших варіантів, які вивчають внутрішні уявлення, які вирішують складні комбінаторні задачі. Вхідні нейрони стають вихідними в кінці повного оновлення. Генеративна змагальна мережа Яна Гудфеллоу (GAN) складається з двох мереж. Часто це комбінація Feed Forwards і Convolutional Neural Nets. Одна генерує контент генеративний, а інша повинна оцінювати контент дискримінаційний. 
 Для цілей генерації даних: = 5а + bc + 7с. Спочатку прописують невеликий скрипт для генерації даних: а = Rand (11000); b = Rand (11000); з = Rand (11000); n = Rand (11000) * 005; у = а * 5 + Ь * с + 7 * з + n, де n - це шум, спеціально доданий, щоб зробити його схожим на реальні дані. Величина шуму становить 01 і є рівномірною. Таким чином, вхід - це набір "a", "b" і "c", а висновок: I =[a; b; c]; O = y. Далі використовують вбудовану функцію matlab newff для генерації моделі.
Для цілей генерації даних: = 5а + bc + 7с. Спочатку прописують невеликий скрипт для генерації даних: а = Rand (11000); b = Rand (11000); з = Rand (11000); n = Rand (11000) * 005; у = а * 5 + Ь * с + 7 * з + n, де n - це шум, спеціально доданий, щоб зробити його схожим на реальні дані. Величина шуму становить 01 і є рівномірною. Таким чином, вхід - це набір "a", "b" і "c", а висновок: I =[a; b; c]; O = y. Далі використовують вбудовану функцію matlab newff для генерації моделі. 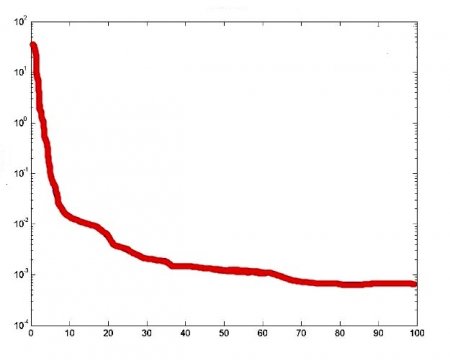 Тепер знову моделюють її на тих же даних і порівнюють вихідні дані: O1 = sim(net,I); plot(1:1000O,1:1000O1). Таким чином, вхідна матриця буде: net.IW{1} -036840.0308 -05402 046400.234005875 19569 -168871.5403 111381.084102439 net.LW{21} -1119909.4589 -10006 -09138
Тепер знову моделюють її на тих же даних і порівнюють вихідні дані: O1 = sim(net,I); plot(1:1000O,1:1000O1). Таким чином, вхідна матриця буде: net.IW{1} -036840.0308 -05402 046400.234005875 19569 -168871.5403 111381.084102439 net.LW{21} -1119909.4589 -10006 -09138
Історія нейронної мережі
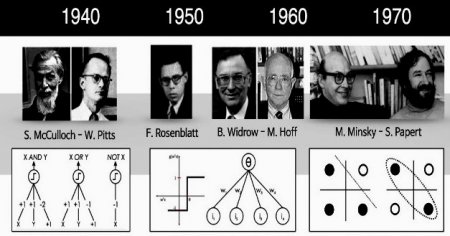
Вчені в області комп'ютеризації давно намагаються змоделювати людський мозок. В 1943 році Уоррен С. МакКаллох і Уолтер Піттс розробили першу концептуальну модель штучної нейронної мережі. У статті «Логічне числення ідей, що відносяться до нервової активності» вони описали приклад нейронної мережі, концепцію нейрона - єдиної клітини, що живе в загальній мережі, отримує вхідні дані, обробляє їх і генерує вихідні сигнали.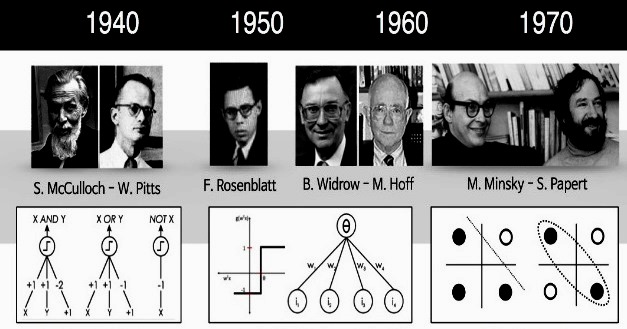

Біологічні обчислювальні машини

Елементи нейронної моделі
Глибоке навчання - термін, використовуваний для складних нейронних мереж, що складаються з декількох шарів. Шари складаються з вузлів. Вузол - це просто місце, де відбувається обчислення, який спрацьовує, коли стикається з достатньою кількістю стимулів. Вузол об'єднує вхідні дані з набору коефіцієнтів або терезів, які або посилюють, або послаблюють цей сигнал, тим самим визначаючи значимість для завдання.Мережі з глибоким навчанням відрізняються від поширених нейронних з одним прихованим шаром. Приклад навчання нейронних мереж – мережі Кохонена.
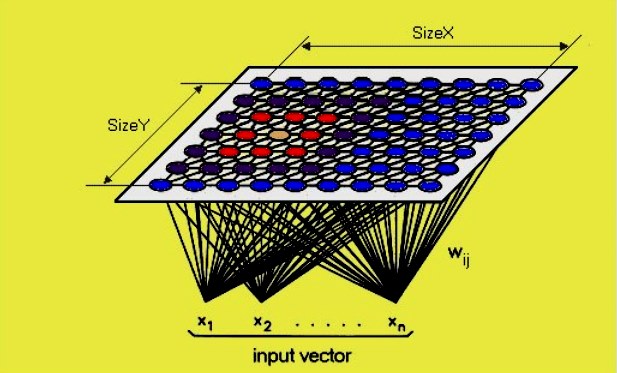
Чорний ящик ANN
Штучні нейронні мережі (ШНМ) - це статистичні моделі, частково змодельовані на біологічних нейронних мережах. Вони здатні обробляти нелінійні відносини між входами і виходами паралельно. Характеризуються такі моделі наявністю адаптивних ваг вздовж шляхів між нейронами, які можуть бути налаштовані алгоритмом навчання, щоб поліпшити всю модель.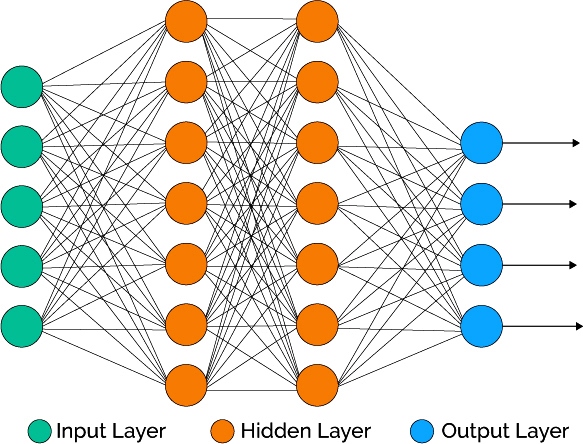
У простій моделі перший шар - це вхідний, за яким слід прихований і, нарешті, вихідний. Кожен може містити один або декілька нейронів. Моделі можуть ставати все більш складними зі збільшенням можливостей абстракції і рішення проблем, кількості прихованих шарів, числа нейронів в кожному даному шарі і кількості колій між ними. Архітектура і налаштування моделі є основними компонентами методів ANN в доповнення до самих алгоритмів навчання. Вони є надзвичайно потужними і вважаються алгоритмами чорного ящика, що означає, що їх внутрішню роботу дуже важко зрозуміти і пояснити.
Алгоритми глибокого навчання
Глибоке навчання - це поняття звучить досить голосно, насправді є просто терміном, що описує певні типи нейронних мереж та пов'язані з ними алгоритми, які споживають необроблені вхідні дані через безліч шарів нелінійних перетворень, щоб обчислити цільової вихід. Необслуживаемое витяг ознак також є областю, в якій глибоке навчання перевершує всі очікування. Приклад навчання нейронних мереж – мережі SKIL.
Оптимальні параметри алгоритму
Алгоритми навчання функціям санкціонують машину на пізнання конкретної задачі, використовуючи відточений набір можливостей для вивчення. Іншими словами, вони вчаться вчитися. Такий принцип успішно використовується в багатьох додатках і вважається одним із передових методів штучного інтелекту. Відповідні алгоритми часто використовуються для контрольованих, неконтрольованих і частково контрольованих завдань. У моделях на основі нейронної мережі число шарів більше, ніж в алгоритмах поверхневого навчання. Малі алгоритми менш складні і вимагають більш глибокого знання оптимальних функцій, які включають вибір і розробку. Навпаки, алгоритми глибокого навчання більше покладаються на оптимальний вибір моделі та її оптимізацію шляхом налаштування. Вони краще підходять для вирішення завдань, коли попереднє знання функцій менш бажано або необхідно, а зафіксовані дані недоступні або не потрібні для використання. Вхідні дані перетворюються у всіх їх шарах за допомогою штучних нейронів або процесорних блоків. Прикладом коду нейронної мережі називають CAP.Значення CAP
CAP використовується для вимірювання в архітектурі моделі глибокого навчання. Більшість дослідників в цій області згодні з тим, що вона має більше двох нелінійних шарів для CAP, а деякі вважають, що CAP, мають більше десяти шарів, вимагають надто глибокого навчання.
Топ сучасних архітектур
Перцептрони вважаються нейронними мережами першого покоління, обчислювальними моделями одного нейрона. Вони були винайдені в 1956 році Френком Розенблатт в роботі «Перцептрон: передбачувана модель зберігання і організації інформації в головному мозку». Перцептрон, також званий мережею прямого зв'язку, передає інформацію від передньої її частини до задньої.Рекурентні нейронні мережі RNN перетворюють вхідну послідовність у вихідну, яка знаходиться в іншій області, наприклад, змінює послідовність звукових тисків в послідовність ідентифікаторів слів. Джон Хопфілд представив Hopfield Net у статті 1982 року «Нейронні мережі та фізичні системи з виникаючими колективними обчислювальними можливостями». У мережі Хопфілда (HN) кожен нейрон зв'язаний з будь-яким іншим. Вони навчаються шляхом встановлення їх значення на бажану схему, після чого можна обчислити вагові коефіцієнти.

Початок роботи SKIL з Python
Глибоке навчання нейронної мережі на прикладі Python зіставляє входи з виходами і знаходить кореляції. Він відомий, як універсальний аппроксиматор, тому що може навчитися наближати невідому функцію f(x) = y між будь-яким входом «x» та будь-яким виходом «y», припускаючи, що вони пов'язані кореляцією або причинно-наслідковим зв'язком. У процесі навчання правильний «f» або спосіб перетворення «x», «y», будь то f(x) = 3x + 12 або f(x) = 9x - 01. Завдання класифікації пов'язані з наборами даних, щоб нейронні мережі виконували кореляцію між мітками і даними. Відомо контрольоване навчання наступних видів: розпізнавання осіб; ідентифікація людей на зображеннях; визначення виразу обличчя: сердите, радісне; ідентифікація об'єктів на зображеннях: знаки зупинки, пішоходи, покажчики смуги руху; розпізнавання жестів у відео; визначення голоси ораторів; класифікація тексту-спаму.Приклад сверточной нейронної мережі
Сверточная нейронна мережа схожа на багатошарову мережа перцептрона. Основною відмінністю є те, що CNN вивчає, як вона структурована і для якої мети використовується. Натхненниками CNN були біологічні процеси. Їх структура має видимість зорової кори, присутньої у тварини. Вони застосовуються в області комп'ютерного зору й успішні досягнення сучасного рівня продуктивності в різних областях досліджень. Перш ніж починають кодувати CNN, для побудови моделі використовують бібліотеку, наприклад, Keras з бэкэндом Tensorflow. Спочатку виконують необхідний імпорт. Бібліотека допомагає будувати сверточную нейронну мережу. Завантажують набір даних mnist через keras. Імпортують послідовну модель keras, в яку можна додати шари згортки та об'єднання, щільні шари, так як вони використовуються для прогнозування міток. Випадаючий шар зменшує переоснащення, а вирівнюючий перетворює тривимірний вектор в одновимірний. Нарешті, імпортуємо numpy для матричних операцій: Y = 2 # значення 2 уявляє, що зображення має цифру 2; Y =[0,0,1,0,0,0,0,0,0,0]# 3-я позиція у векторі зроблена 1; # Тут значення класу перетворюється в матрицю двійкового класу. Алгоритм будівництва: Додають до послідовної моделі надточні шари максимальний пул. Додають випадають шари між ними. Випадаючий випадковим чином відключає деякі нейрони в мережі, що змушує дані знаходити нові шляхи і зменшує переоснащення. Додають щільні шари, які використовуються для передбачення класу (0-9). Компілюють модель з категоріальною функцією крос-ентропійної втрати, оптимізатором Adadelta і метрикою точності. Після навчання оцінюють втрати і точність моделі за даними випробувань і роздруковують її.
Моделювання в Matlab
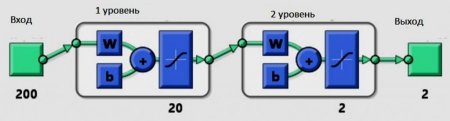
Наведемо простий приклад нейронних мереж Матлаб-моделювання. Припускаючи, що "а" модель має три входи "a", "b" і "c" і генерує вихід "y".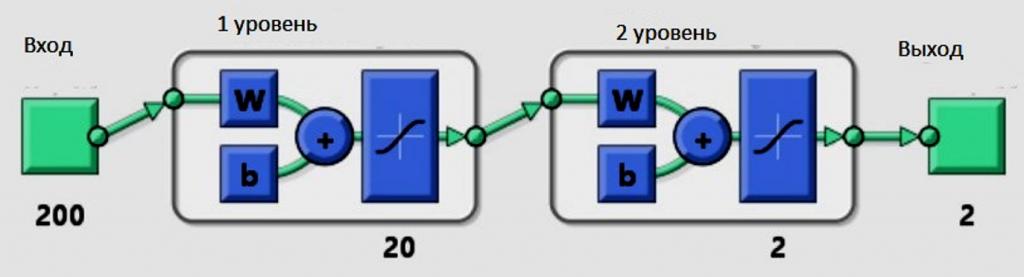
Приклади завдань нейронних мереж
Спочатку створюють матрицю R розміром 3 * 2. Перший стовпець покаже мінімум всіх трьох входів, а другий - максимум трьох входів. У цьому випадку три входи знаходяться в діапазоні від 0 до 1 тому: R =[0 1; 0 1; 0 1]. Тепер створюють матрицю розміру, яка має v-розмір усіх шарів: S =[51]. Тепер викликають функцію newff наступним чином: net = newff ([0 1; 0 1; 0 1], S, {'tansig', 'purelin'}). Нейронна модель {'tansig', 'purelin'} показує функцію відображення двох шарів. Навчають її з даними, які створені раніше: net = train(net,I,O). Мережа навчена, можна побачити криву продуктивності, як вона навчається.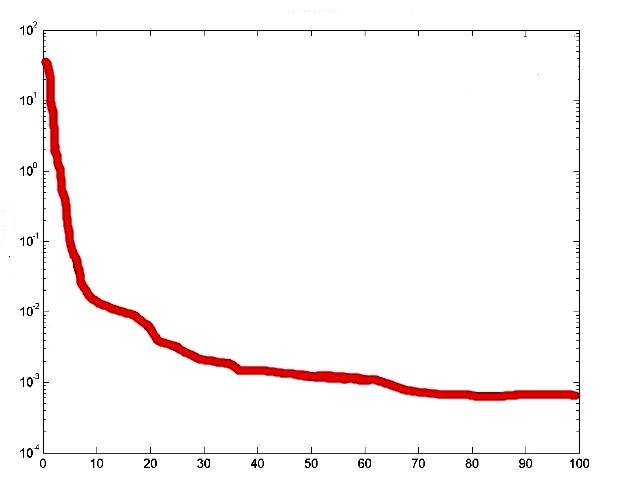
Програми штучного інтелекту
Приклади реалізації нейронної мережі включають в себе онлайн-рішення для самообслуговування та створення надійних робочих процесів. Існують моделі глибокого навчання, використовувані для чат-ботів, оскільки вони продовжують розвиватися, можна очікувати, що ця область буде більше використовуватися для широкого кола підприємств. Області застосування: Автоматичний машинний переклад. Він не є чимось новим, глибоке навчання допомагає поліпшити автоматичний переклад тексту за допомогою складених мереж і дозволяє переводити зображення. Простий приклад застосування нейронних мереж - додавання кольору до чорно-білих зображень та відео. Його можна автоматично робити за допомогою моделей з поглибленим вивченням. Машини вивчають пунктуацію, граматику і стиль фрагмента тексту і можуть використовувати розроблену ним модель для автоматичного створення абсолютно нового тексту з належним написанням, граматикою і стилем тексту. Штучні нейронні мережі ANN і більш складна техніка глибокого навчання є одними з найбільш досконалих інструментів для вирішення складних завдань. Хоча бум застосування найближчим часом малоймовірне, прогрес технологій і додатків штучного інтелекту, безумовно, буде захоплюючим. Незважаючи на те що дедуктивні міркування, логічні висновки та прийняття рішень за допомогою комп'ютера сьогодні ще дуже далекі від досконалості, вже досягнуті значні успіхи в застосуванні методів штучного інтелекту і пов'язаних з ними алгоритмів.Цікаво по темі

Застосування функції PHP random
Випадкові числа в програмуванні знаходять застосування для створення унікальних імен змінних і файлів, формування презентацій, виведення інформації

Функція Random C++
Починаючи з версії C++11 у стандарті мови були значно розширені засоби для роботи з випадковими числами (далі, СЧ). СЧ використовуються в багатьох

Налаштування статичної маршрутизації
Статична маршрутизація, альтернатива динамічної маршрутизації – це процес, в якому адміністратор системної мережі вручну налаштовував мережеві

PLC-адаптер: ціна та відгуки
PLC-адаптери: принцип роботи, види, переваги та недоліки. Нюанси роботи адаптерів і безпека передачі даних у PLC-мережі.
