MySQL LIMIT: опис, синтаксис, приклади і рекомендації
Вибір конкретної кількості записів з великого набору - ідея хороша, але коли набір дійсно великий, виникає ефект деградації ідеї. Вибір декількох записів з деякої позиції створює реальне падіння продуктивності: перед досягненням мети MySQL переглядає інші записи, витрачаючи на це час.  Формально MySQL limit може працювати з початку таблиці або з її кінця. Вибірка може визначати конкретну кількість записів, починаючи з заданої позиції. Завжди може виникнути випадок, тобто настання найгіршої ситуації можливо. Зазвичай загальний потік клієнтів обумовлює загальний статистичний режим роботи, але передбачити різні ситуації необхідно, це серйозне рішення на користь сайту.
Формально MySQL limit може працювати з початку таблиці або з її кінця. Вибірка може визначати конкретну кількість записів, починаючи з заданої позиції. Завжди може виникнути випадок, тобто настання найгіршої ситуації можливо. Зазвичай загальний потік клієнтів обумовлює загальний статистичний режим роботи, але передбачити різні ситуації необхідно, це серйозне рішення на користь сайту.
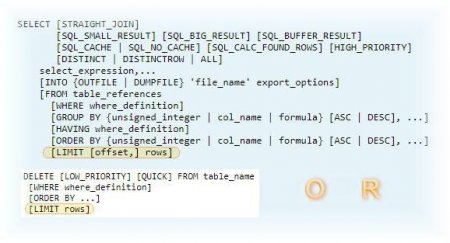 Запит на вибірку (select) передбачає два числа: зміщення "O" і "R", запит на видалення (delete) записується одним числом - кількістю видаляються записів "R".
Запит на вибірку (select) передбачає два числа: зміщення "O" і "R", запит на видалення (delete) записується одним числом - кількістю видаляються записів "R".
Конструкція, де велика значення "R" мало цікавитиме розробника та користувача: MySQL delete limit. І то далеко не у всіх випадках. У цій конструкції основний тягар відповідальності лягає на умову вибірки (where) видалених записів. В цілях безпеки і контролю за процесом видалення записів розробник зазвичай, зацікавлений у використанні механізму AJAX і видалення записів невеликими порціями. При такому механізмі відвідувач сайту не помітить затримки в роботі конструкції delete. Ніщо не заважає зробити це ефектно і приховати фатальні затримки часу за діалогом формування контенту.
Ніщо не заважає зробити це ефектно і приховати фатальні затримки часу за діалогом формування контенту.
Всі недоліки ставляться до самої концепції реляційних відносин. Що робити, ця концепція настільки фундаментально і надійно працює, нічого не залишається, як рахуватися з її особливостями і враховувати їх. Сучасний рівень розвитку апаратного забезпечення, якісна реалізація функціоналу по всіх інструментах MySQL (limit - не виняток) забезпечують доступність великих обсягів даних при високих швидкостях роботи і, що найважливіше, вибірки. Це нормальне, стандартне рішення. У більшості випадків так прийнято поступати. У програмуванні досить давно затребувана ідея поділу праці. Розробник робить сайти, адміністратор керує роботою всього, що забезпечує оптимізацію використання сайту. У критичних ситуаціях, коли таблиці бази даних великі, доводиться відходити від прийнятих канонів. Потрібно щось міняти в організації даних.
Це нормальне, стандартне рішення. У більшості випадків так прийнято поступати. У програмуванні досить давно затребувана ідея поділу праці. Розробник робить сайти, адміністратор керує роботою всього, що забезпечує оптимізацію використання сайту. У критичних ситуаціях, коли таблиці бази даних великі, доводиться відходити від прийнятих канонів. Потрібно щось міняти в організації даних.  Але що тут дивного? Таблиця - це безліч записів, що містять різні дані, відповідно типам полів (колонок, шапці таблиці). Запит MySQL query limit звертається до таблиці "big_info" і вибирає c 100000 позиції рядка 24 відображення в браузері.
Але що тут дивного? Таблиця - це безліч записів, що містять різні дані, відповідно типам полів (колонок, шапці таблиці). Запит MySQL query limit звертається до таблиці "big_info" і вибирає c 100000 позиції рядка 24 відображення в браузері.
У такому рішенні у вибірці бере участь 100024 рядка - це довго. Але якщо змінити ситуацію і всю таблицю "big_info" розписати на кілька сотень таблиць "big_info[0999]" по 1000 записів, то проблема виникне лише при запиті MySQL "order by * limit O, R", оскільки сортування буде вкрай ускладнена. Втім, не тільки сортування, але і будь-яка інша операція над усіма записами неможлива засобами бази даних над таблицею, яка представлена кількома таблицями. Індекс в такому контексті в MySQL відсутня. Реляційні відносини передбачають чіткість: є база, нею є таблиці, таблиці - колонки і запису. Ну ще є "примочки": збережені процедури, тригери, умови та інші деталі. Чим більший потік відвідувачів, тим більше закономірності до потреб вибірки. MySQL limit завжди виконується точно і завжди з конкретної причини. Зібрати конкретні причини ніколи не складе праці. Прив'язати до кожної конкретної причини результати MySQL limit в кожному конкретному випадку - тривіальна задача. Виходить не посторінкова організація таблиці у форматі сотень однотипних сторінок, а конус затребуваності інформації. Тільки в фатальних випадках або при заході на сторінку інформаційно місткого відвідувача відбувається вибірка великого обсягу даних. У звичайному режимі - вибираються крихти. Власний кеш елементарно вирішує проблему швидкості: вибірка йде по ключу «конкретна причина» з маленької таблиці результатів останніх операцій вибірки з однієї великої таблиці.
Чим більший потік відвідувачів, тим більше закономірності до потреб вибірки. MySQL limit завжди виконується точно і завжди з конкретної причини. Зібрати конкретні причини ніколи не складе праці. Прив'язати до кожної конкретної причини результати MySQL limit в кожному конкретному випадку - тривіальна задача. Виходить не посторінкова організація таблиці у форматі сотень однотипних сторінок, а конус затребуваності інформації. Тільки в фатальних випадках або при заході на сторінку інформаційно місткого відвідувача відбувається вибірка великого обсягу даних. У звичайному режимі - вибираються крихти. Власний кеш елементарно вирішує проблему швидкості: вибірка йде по ключу «конкретна причина» з маленької таблиці результатів останніх операцій вибірки з однієї великої таблиці.  Реляційні відношення занадто довго володіли пальмою першості, але поступатися дорогу донині не мають наміру: просто нікому. Інших варіантів організації даних, які забезпечують моментальну навігацію по більших обсягів інформації, не придумав навіть сверхлидер галузі «Велика інформація» - Oracle. Але Oracle забезпечив хороший досвід і відмінні знання в реалізації SQL-мови та її діалектів. На функціонал MySQL це наклало певний відбиток якості. Розробник може сміливо використовувати конструкцію MySQL limit на одній таблиці даних і мати вільний доступ до оптових операцій над цією великою таблицею.
Реляційні відношення занадто довго володіли пальмою першості, але поступатися дорогу донині не мають наміру: просто нікому. Інших варіантів організації даних, які забезпечують моментальну навігацію по більших обсягів інформації, не придумав навіть сверхлидер галузі «Велика інформація» - Oracle. Але Oracle забезпечив хороший досвід і відмінні знання в реалізації SQL-мови та її діалектів. На функціонал MySQL це наклало певний відбиток якості. Розробник може сміливо використовувати конструкцію MySQL limit на одній таблиці даних і мати вільний доступ до оптових операцій над цією великою таблицею.  Кожен повинен займатися своєю справою і робити це справа максимально ефективним чином. Реляційні відношення ніколи не відімруть - вони властиві даними, це їх невід'ємна складова. Але в реалізації баз даних у реляційних відносин не вистачає семантики. Ключова організація, індекси для доступу до записів - це не той зміст, який забезпечує швидкий доступ до інформації. Послідовна організація пам'яті машин та емуляція асоціативного доступу до інформації - реальна причина втрати часу при доступі до великої таблиці для вибірки частини інформації при дотриманні її цілісності для виконання групових операцій.
Кожен повинен займатися своєю справою і робити це справа максимально ефективним чином. Реляційні відношення ніколи не відімруть - вони властиві даними, це їх невід'ємна складова. Але в реалізації баз даних у реляційних відносин не вистачає семантики. Ключова організація, індекси для доступу до записів - це не той зміст, який забезпечує швидкий доступ до інформації. Послідовна організація пам'яті машин та емуляція асоціативного доступу до інформації - реальна причина втрати часу при доступі до великої таблиці для вибірки частини інформації при дотриманні її цілісності для виконання групових операцій.  Але вихід все ж таки є: кожне конкретне застосування - це питання, на який потрібно знайти швидкий відповідь. Потрібно зробити швидкий вибір (MySQL limit) при тому, що інший функціонал (MySQL order by, group by, join & where) не постраждає, таблиця не буде розбиватися на безліч однотипних частин, а процедури кешування будуть потрапляти оновлені дані відразу після їх поновлення, а не тоді, коли на них надійде чергова «конкретна причина». Мова SQL - це хороший мову, але якщо до нього додати асоціації, він стане ще краще.
Але вихід все ж таки є: кожне конкретне застосування - це питання, на який потрібно знайти швидкий відповідь. Потрібно зробити швидкий вибір (MySQL limit) при тому, що інший функціонал (MySQL order by, group by, join & where) не постраждає, таблиця не буде розбиватися на безліч однотипних частин, а процедури кешування будуть потрапляти оновлені дані відразу після їх поновлення, а не тоді, коли на них надійде чергова «конкретна причина». Мова SQL - це хороший мову, але якщо до нього додати асоціації, він стане ще краще.

Синтаксис конструкції LIMIT
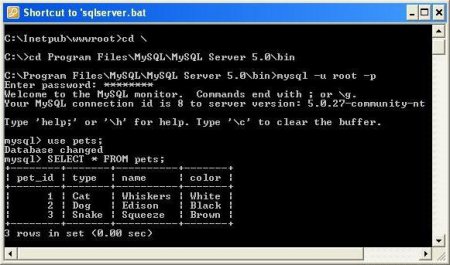
В офіційних джерелах MySQL limit syntax позначений, як показано на зображенні нижче, у контексті запитів select і delete.
Великі значення limit "O, R"
MySQL limit: синтаксис допускає вибірку значень за будь-якої схеми. Базові умови: "O" - зсув першої обраної записи, "R" - кількість вибраних записів. Проблема полягає в тому, що якщо "O" = 9000 то перед тим як MySQL вибере 9001 запис, він пройдеться по першим 9000. Якщо R = 1000 то в цілому у вибірці «візьме участь» 10000 записів. MySQL select limit може працювати з початку таблиці або з її кінця, в залежності від напрямку сортування записів asc /desc. Варіант роботи з кінця таблиці не є перспективним рішенням, хоча в деяких ситуаціях без нього важко обійтися.Конструкція, де велика значення "R" мало цікавитиме розробника та користувача: MySQL delete limit. І то далеко не у всіх випадках. У цій конструкції основний тягар відповідальності лягає на умову вибірки (where) видалених записів. В цілях безпеки і контролю за процесом видалення записів розробник зазвичай, зацікавлений у використанні механізму AJAX і видалення записів невеликими порціями. При такому механізмі відвідувач сайту не помітить затримки в роботі конструкції delete.
Вибірка однією унікальною запису
Правильне умова where і запит "limit 1" MySQL виконає моментально. Але видаляти або вибирати по одному запису - далеко не завжди хороше рішення. Зазвичай порційна вибірка по всім записам таблиці використовується для сторінкової організації даних (наприклад, коментарі, статті, відгуки про товари). Рішення про формування вмісту веб-сторінки має бути прийнято моментально, але при класичному використання MySQL limit O, R швидко буде обраний тільки перший десяток першої сотні записів, потім почнуться затримки. Між тим, не все так складно, можна вибирати швидко по запису, але вигравати за рахунок дизайну і логіки виведення запису в браузер відвідувача.
Реляційні відношення в MySQL
MySQL - відмінний інструмент для представлення та обробки інформації. Розробник має в своєму розпорядженні якісний діалект мови SQL і зручний механізм формування запитів. Помилки і непередбачені ситуації протоколюються, доступ до даних адмініструється аж до рівня базових операцій.Всі недоліки ставляться до самої концепції реляційних відносин. Що робити, ця концепція настільки фундаментально і надійно працює, нічого не залишається, як рахуватися з її особливостями і враховувати їх. Сучасний рівень розвитку апаратного забезпечення, якісна реалізація функціоналу по всіх інструментах MySQL (limit - не виняток) забезпечують доступність великих обсягів даних при високих швидкостях роботи і, що найважливіше, вибірки.
Великі обсяги і стандартний кеш
Буферизація даних перед записом і після вибірки - ідея чудова, веде свій початок з далеких 80-х років. Кешування стало модним на всіх рівнях обробки даних від процесорного, мережевого, до, природно, рівня http-сервера і власне баз даних. Розробник може звернутися до адміністратора сервера або самостійно налаштувати кешування на рівні Apache і MySQL або інший використовуваної комбінації програмних засобів, що забезпечують функціонування веб-ресурсу і сервера MySQL.
Таблична посторінкова організація
Розробники звикли: реляційна база даних - це сукупність таблиць, взаємопов'язаних один з одним по ключам. Така проста ідея, як таблиця, представлена масою однотипних сторінок з одним ім'ям, але різними індексами, що виходить за межі звичного уявлення.
У такому рішенні у вибірці бере участь 100024 рядка - це довго. Але якщо змінити ситуацію і всю таблицю "big_info" розписати на кілька сотень таблиць "big_info[0999]" по 1000 записів, то проблема виникне лише при запиті MySQL "order by * limit O, R", оскільки сортування буде вкрай ускладнена. Втім, не тільки сортування, але і будь-яка інша операція над усіма записами неможлива засобами бази даних над таблицею, яка представлена кількома таблицями. Індекс в такому контексті в MySQL відсутня. Реляційні відносини передбачають чіткість: є база, нею є таблиці, таблиці - колонки і запису. Ну ще є "примочки": збережені процедури, тригери, умови та інші деталі.
Власний кеш і поняття актуальності
Хороша ідея «Яндекса» - «тепловізор»: теплова карта кліків веб-сторінок. Цей інструмент показує в спектральному колірному рішенні поширення актуальності інтересу відвідувачів з «території» сторінки. Судячи з усього, скоро з'явиться новий шкільний предмет - географія веб-сторінки: де і що розмістити. Хороше доповнення до загальної географії Ця ідея, переложенная на територію записів великий таблиці бази даних, дозволяє сформулювати об'єктивний теза: не вся територія записів затребувана і не завжди.
Сортування та інші оптові операції
Проблема великих обсягів даних впирається в продуктивність апаратно-програмного забезпечення. Сьогодні досягнуто приголомшливий рівень продуктивності, але обсяги даних теж різко зросли. Коли зростає швидкість і якість доріг, адекватно зростає потреба у швидкому переміщенні і моментальному вирішенні завдань. Проста операція сортування, додавання запису або пошуку даних, зачіпає прямо або побічно усі записи великий таблиці, - потенційний гальма, гарантована втрата продуктивності.
Природне сприйняття інформації
Людина сприймає й обробляє, здебільшого несвідомо, величезні обсяги інформації, які недоступні найдосконалішим інструментів від Oracle. Але він не може особливо пишатися цим. Oracle може робити міграції таких обсягів даних і виконувати такі сортування, для виконання яких потрібно не одне людське життя не одній сотні примірників.
Інформаційні об'єкти і природні асоціації
Уникнути послідовності у виконанні операцій розробник поки не може. Так влаштований комп'ютерний світ. Комп'ютер має один процесор, а багатоядерні і багатопроцесорні варіанти - це все ж не нейронна організація паралельної обробки інформації, яку використовує людське мислення. Розробка алгоритму завжди апелює до одного процесу, хоч і разбиваемому на безліч потоків. Програмування поки йде на одному рівні, навіть коли код побудований у форматі системи взаємодіючих об'єктів, примірники яких функціонують самі по собі. Питання вже не стільки в якості будови інформаційних систем у вигляді самостійних об'єктів, скільки в середовищі, яка забезпечує їх функціонування. Середа - послідовна, а не паралельна. Зростання кількості ядер і кількості процесорів в одному комп'ютері, планшеті або іншому девайсі не робить їх асоціативними обчислювальними пристроями.Цікаво по темі

Групування записів MySQL: group by
Групування й аналіз записів таблиць бази даних представляють практичний інтерес у багатьох областях застосування. Рішення такого роду задач засобами

Вибір унікальних записів в запиті MySQL: select distinct
Простота запиту - це мистецтво. Легко сприймається відображення інфраструктури завдання на мінімально необхідну кількість таблиць і зв'язків між ними

Доступ до результатів вибірки через MySQL fetch array
MySQL fetch array обробляє результати вибірки з бази даних і повертає в якості результату звичайний, асоціативний або обидва масиву відразу. Фактично

Оператор Delete видалення MySQL
Видалення записів таблиць бази даних - необхідна операція для підтримки порядку в записах. Використання операції видалення може бути виконано різними

Видалення дублікатів MySQL distinct
Видалення дублікатів MySQL distinct - потрібна операція. Багато вирішення завдань представлення та обробки інформації за допомогою реляційних баз
MySQL select select from: оператор вибірки
MySQL - одна з найпопулярніших систем управління базами даних (СУБД). У даній статті ми розглянемо базову функціональність оператора вибірки SELECT,