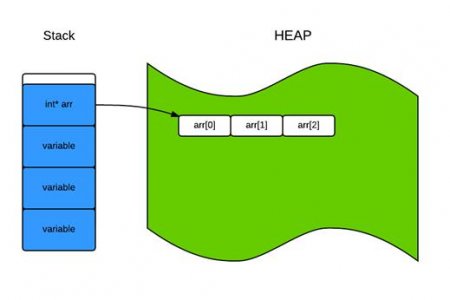
Двійковий пошук - розбір алгоритму на мові C++
Послідовний пошук
Це найпростіший алгоритм пошуку значення в масиві. Використовує метод почергового порівняння елементів масиву зі значенням ключа. Здійснюється зазвичай, зліва направо. Використовується, якщо елементів у масиві трохи список не впорядкований. Абсолютно неефективний у великих масивах, де зазвичай застосовується двійковий пошук. Алгоритм працює наступним чином:Порівнюємо значення ключа зі значенням елемента масиву. Якщо значення рівні, повертаємо отримане значення. Якщо ні – збільшуємо значення змінної циклу на одиницю і порівнюємо з наступним елементом масиву.

Индексно-послідовний пошук
Більш ефективний спосіб пошуку значення у відсортованому масиві. Але більш вимогливий до ресурсів.Бінарний пошук
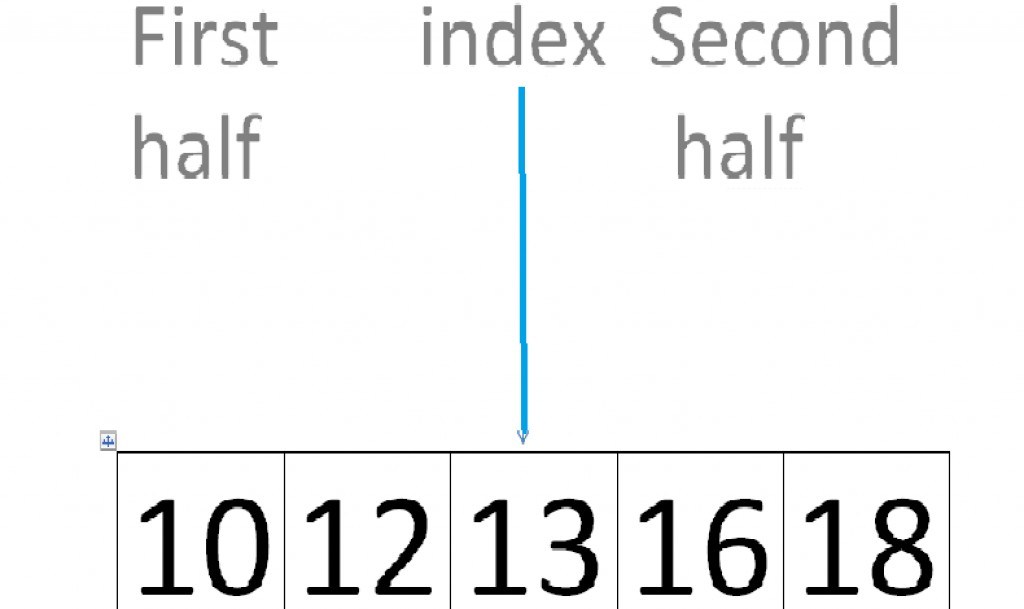
Бінарний (двійковий) пошук — це алгоритм знаходження елемента масиву послідовним діленням масиву навпіл і сравниванием вихідного числа з числом з середини масиву. Якщо число з середини менше шуканого, шукаємо далі, у другій частині, якщо більше — продовжуємо пошук в першій. Алгоритм найшвидший з усіх перерахованих і працює наступним чином:Спочатку дізнаємося значення об'єкту у середині масиву. Перевіряємо на відповідність з вихідним значенням. Якщо значення з середини менше вихідного, то продовжуємо пошук у другій половині, якщо більше — шукаємо в першій. В отриманій половині поступаємо таким же чином: ділимо її на половину і порівнюємо отримане значення. Пошук відбувається до моменту, поки початкове значення не стане дорівнює значенню в масиві. Якщо такого не відбувається — значить даного значення в масиві немає.
Переповнення обраного типу даних
Щоб дізнатися значення в середині масиву, необхідно скласти праве і ліве значення, і розділити на два. Тобто: Середина масиву = Ліве значення + (Ліве значення - Праве значення)/2 Тут є небезпека переповнення типу даних при операції додавання. Якщо в масиві є значення настільки великих розмірів, доводиться використовувати різні прийоми, щоб уникнути ризику. Нижче представлені стандартні помилки при розробці двійкового пошуку.
Помилки значень
Або помилки на одиницю. Дуже важливо врахувати наступні варіанти:
- Порожній масив.
- Значення відсутня.
- Вихід за межі масиву.
Кілька примірників
Необхідно врахувати, що у разі існування в масиві декількох однакових примірників ключа програма повинна знаходити певний (перший, останній, наступний за ним).
<script type="text/jаvascript">
var blockSettings2 = {blockId:"R-A-271049-5",renderTo:"yandex_rtb_R-A-70350-39",async:!0};
if(document.cookie.indexOf("abmatch=") >= 0) blockSettings2.statId = 70350;
!function(a,b,c,d,e){a[c]=a[c]||[],a[c].push(function(){Ya.Context.AdvManager.render(blockSettings2)}),e=b.getElementsByTagName("script")[0],d=b.createElement("script"),d.type="text/jаvascript",d.src="//an.yandex.ru/system/context.js",d.async=!0e.parentNode.insertBefore(d,e)}(this,this.document,"yandexContextAsyncCallbacks");
Розберемо реалізації даного алгоритму на мові програмування C плюс плюс. Необхідно враховувати, що двійковий пошук працює тільки з відсортованим масивом! Якщо масив попередньо не відсортувати, то результат обчислень буде невірним.
Нижче наведено код на C ++. Спочатку ініціалізується масив цілочисельних змінних arr, розміром десять. Далі оператор cin в циклі for очікує введення десяти значень від користувача (рядок десять).
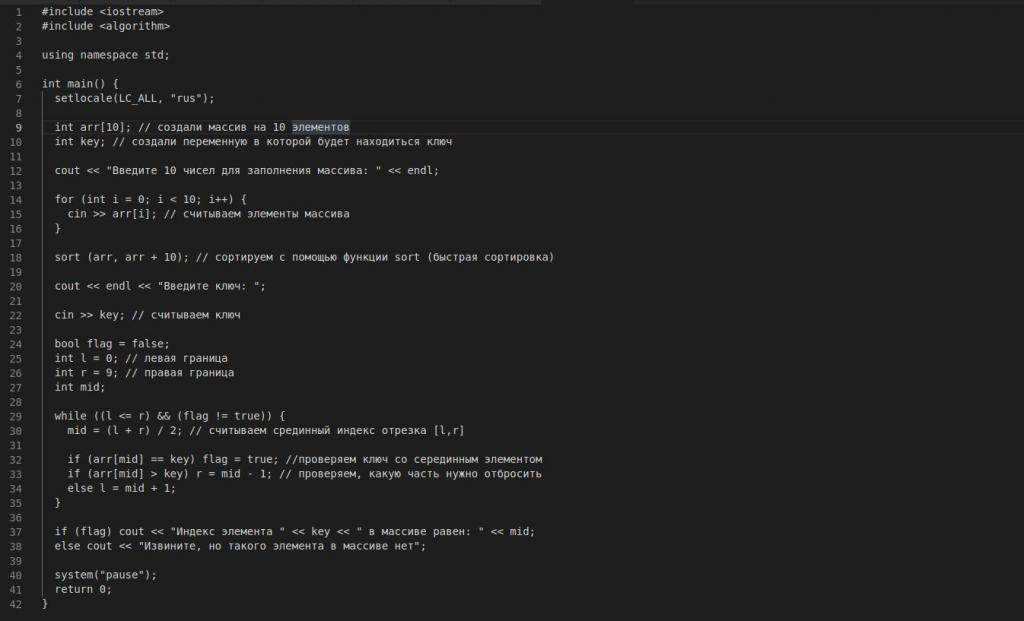
У двадцятої рядку програма чекає від користувача введення значення ключа.
Рядки 29 – 35 являють собою реалізований алгоритм бінарного пошуку. У ході виконання програми в змінну mid записується значення середнього елемента за формулою:
Середина масиву (mid) = (Ліве значення (l) + Праве значення (r))/2
Рядком
arr[mid]==key Перевіряється, дорівнює чи серединное значення значенням ключа. Якщо одно, то значення змінної flag змінюється значення ІСТИНА, тобто задача вирішена. Якщо ж серединное значення більше значення нашого ключа, то правій частині (змінна r) присвоюється mid. Якщо навпаки, то mid кладеться в r. Останнє — це перевірка булевої змінної flag. Переваги бінарного пошуку
Двійковим пошуком слід користуватися, якщо потрібна швидка робота програми. І написати такий алгоритм не складе труднощів навіть починаючому програмісту. Але дуже важливо враховувати всі крайні випадки: вихід за межі масиву, відсутність шуканого значення, помилка переповнення даних.
Недоліки
Для коректної роботи алгоритму масив необхідно попередньо сортувати. Для цього в мові програмування C++ можна скористатися готовою функцією sort(). І ще один важливий момент, на який необхідно звернути увагу, вивчаючи двійковий пошук в C і C++. Цей алгоритм можна використовувати тільки з певними структурами даних. Наприклад, сюди не підійдуть структури, що використовують зв'язні списки.