Алгоритми стиснення: опис, основні прийоми, характеристики
Стиснення є приватним випадком кодування, основною характеристикою якого є те, що результуючий код менше вихідного. Процес заснований на пошуку повторень в інформаційних рядах і збереження тільки однієї поруч з кількістю повторень. Таким чином, наприклад, якщо послідовність з'являється у файлі, як «AAAAAA», займаючи 6 байтів, він буде збережений, як «6A», який займає 2 байти, в алгоритмі стиснення RLE. 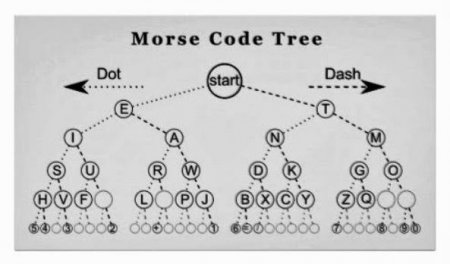 Азбука Морзе, винайдена в 1838 році - перший відомий випадок стиснення даних. Пізніше, коли в 1949 році мейнфрейм-комп'ютери почали завойовувати популярність, Клод Шеннон і Роберт Фано винайшли кодування, названого в честь авторів - Шеннона-Фано. Це шифрування привласнює коди символів в масиві даних по теорії ймовірності.
Азбука Морзе, винайдена в 1838 році - перший відомий випадок стиснення даних. Пізніше, коли в 1949 році мейнфрейм-комп'ютери почали завойовувати популярність, Клод Шеннон і Роберт Фано винайшли кодування, названого в честь авторів - Шеннона-Фано. Це шифрування привласнює коди символів в масиві даних по теорії ймовірності.
Тільки в 1970-х з появою інтернету і онлайн-сховищ, були реалізовані повноцінні алгоритми стиснення. Коди Хаффмана динамічно генерувалися на базі вхідної інформації. Ключова відмінність між кодування Шеннона-Фано і кодування Хаффмана полягає в тому, що в першому дерево ймовірності будувалося знизу вгору, створюючи неоптимальний результат, а в другому - зверху вниз. У 1977 році, Авраам Лемпель і Джейкоб Зів видали свій інноваційний метод LZ77 що використовує більш модернізований словник. У 1978 році, та ж команда авторів, видала вдосконалений алгоритм стиснення LZ78. Який використовує новий словник, аналізує вхідні дані і генерує статичні словник, а не динамічний, як у 77 версії.
Стиснення з втратами назавжди видаляє біти даних, які є надлишковими, неважливими або непомітними. Воно корисно з графікою, аудіо, відео та зображеннями, де видалення деяких бітів практично не чинить помітного впливу на подання контенту. Як видно, кореневий вузол дерева створений, далі призначаються коди.
Як видно, кореневий вузол дерева створений, далі призначаються коди.
 І залишилося тільки упакувати біти в групи по вісім, тобто в байти:
І залишилося тільки упакувати біти в групи по вісім, тобто в байти:
01110010
11010101
11111011
00010010
11010101
11110111
10111001
10000000
0x72
0xd5
0xFB
0x12
0xd5
0xF7
0xB9
0x80
Всього вісім байтів, а вихідний текст був 23. Потім, коли він захоче прочитати текст назад, він замінить кожен примірник (h) на «howtogeek», повертаючись до вихідної фрази. Це демонструє алгоритм стиснення даних без втрат, оскільки дані, які вводяться, збігаються з одержуваними.
Потім, коли він захоче прочитати текст назад, він замінить кожен примірник (h) на «howtogeek», повертаючись до вихідної фрази. Це демонструє алгоритм стиснення даних без втрат, оскільки дані, які вводяться, збігаються з одержуваними. 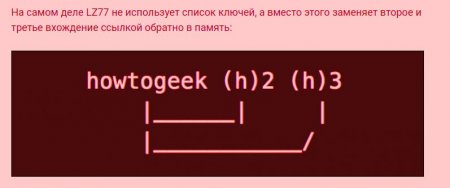 Це ідеальний приклад, коли більша частина тексту стискається за допомогою декількох символів. Наприклад, слово «це» буде стисло, навіть якщо воно зустрічається в таких словах, як «це», «їх» і «цього». З повторюваними словами можна отримати величезні коефіцієнти стиснення. Наприклад, текст зі словом «howtogeek», повтореним 100 разів має розмір три кілобайта, при компресії займе всього 158 байт, тобто з 95% "зменшенням".
Це ідеальний приклад, коли більша частина тексту стискається за допомогою декількох символів. Наприклад, слово «це» буде стисло, навіть якщо воно зустрічається в таких словах, як «це», «їх» і «цього». З повторюваними словами можна отримати величезні коефіцієнти стиснення. Наприклад, текст зі словом «howtogeek», повтореним 100 разів має розмір три кілобайта, при компресії займе всього 158 байт, тобто з 95% "зменшенням".
Це, звичайно, досить екстремальний приклад, але наочно демонструє властивості алгоритмів стиснення. У загальній практиці він становить 30-40% з текстовим форматом ZIP. Алгоритм LZ77 застосовується до всіх двійковим даними, а не тільки до тексту, хоча останній легше стиснути через повторюваних слів.
Відео працює трохи інакше, ніж зображення. Зазвичай алгоритми стиснення графічної інформації використовують тим, що називається «міжкадрових стисненням», яке обчислює зміни між кожним кадром і зберігає їх. Так, наприклад, якщо є відносно нерухомий знімок, який займає декілька секунд відео, він буде "зменшений" в один. Межкадровое стиснення забезпечує цифрове телебачення і веб-відео. Без нього відео важило сотнями гігабайт, що більше середнього розміру жорсткого диска в 2005 році. Стиснення аудіо працює дуже схоже на стиснення тексту і зображень. Якщо JPEG видаляє деталі зображення, яке невидимі людським оком, стиснення звуку робить, те ж саме для звуків. MP3 використовує бітрейт, в діапазоні від нижнього рівня 48 і 96 кбіт/с (нижня межа) до 128 і 240 кбіт/с (досить хороший) до 320 кбіт/с (високоякісний звук), і почути різницю можна тільки з виключно хорошими навушниками. Існують кодеки стиснення без втрат для звуку, основним з яких є FLAC і використовує кодування LZ77 для передачі звуку без втрат. Прогони значень, що кодуються, як символ, за яким слід довжина прогону. Можна правильно відновити вихідний потік. Якщо довжина серії <= 2 символа, имеет смысл просто оставить их без изменения, например, как в конце потока с «bb». В деяких рідкісних випадках отримують додаткову економію, застосовуючи перетворення з алгоритмами стиснення з втратами до частин контенту перед застосуванням безпотерного методу. Оскільки в цих перетвореннях файли не підлягають відновлення до вихідного стану, ці "процеси" зарезервовані для текстових документів. Які не постраждають від втрати інформації, наприклад, скорочення числа з плаваючою комою тільки до двох значущих десяткових розрядів.
Прогони значень, що кодуються, як символ, за яким слід довжина прогону. Можна правильно відновити вихідний потік. Якщо довжина серії <= 2 символа, имеет смысл просто оставить их без изменения, например, как в конце потока с «bb». В деяких рідкісних випадках отримують додаткову економію, застосовуючи перетворення з алгоритмами стиснення з втратами до частин контенту перед застосуванням безпотерного методу. Оскільки в цих перетвореннях файли не підлягають відновлення до вихідного стану, ці "процеси" зарезервовані для текстових документів. Які не постраждають від втрати інформації, наприклад, скорочення числа з плаваючою комою тільки до двох значущих десяткових розрядів.  Сьогодні більшість систем стиснення тексту працюють, об'єднуючи різні перетворення даних для досягнення максимального результату. Зміст кожного етапу системи полягає в тому, щоб виконати перетворення таким чином, щоб наступний етап міг продовжити ефективне стиснення. Сумування цих етапів дає невеликий файл, який можна відновити без втрат. Існує буквально сотні форматів і систем стиснення, кожен з яких має свої плюси і мінуси по відношенню до різних типів даних.
Сьогодні більшість систем стиснення тексту працюють, об'єднуючи різні перетворення даних для досягнення максимального результату. Зміст кожного етапу системи полягає в тому, щоб виконати перетворення таким чином, щоб наступний етап міг продовжити ефективне стиснення. Сумування цих етапів дає невеликий файл, який можна відновити без втрат. Існує буквально сотні форматів і систем стиснення, кожен з яких має свої плюси і мінуси по відношенню до різних типів даних.  Сьогодні в інтернеті використовують два широко використовуваних алгоритмів стиснення тексту HTTP: DEFLATE і GZIP. DEFLATE - зазвичай об'єднує дані, із застосуванням LZ77 кодування Хаффмана. GZIP – файл використовує DEFLATE всередині, поряд з деякими цікавими блокуваннями, евристикою фільтрації, заголовком і контрольною сумою. В цілому, додаткове блокування та евристика, використовують GZIP, дають якісні коефіцієнти стиснення, ніж просто один DEFLATE. Протоколи даних наступного покоління - SPDY і HTTP2.0 підтримують стиснення заголовків з допомогою GZIP, тому більша частина веб-стека буде використовувати і в майбутньому. Більшість розробників просто завантажують незжатий контент і покладаються на веб-сервер для "зменшення" даних на льоту. Це дає відмінні результати і простий у використанні алгоритм стиснення графічних зображень. За замовчуванням на багатьох серверах встановлений GZIP з рівнем 6 найбільший рівень якого дорівнює 9. Це зроблено навмисно, що дозволяє серверам компресувати дані швидше за рахунок більшого вихідного файлу. Формати BZIP2 і LZMA, що створюють більш компактні форми чим GZIP, які при цьому розпаковуються швидше. LZMA можна вважати далеким родичем GZIP. Обидва вони починаються з популярного словника LZ, за яким слід система статистичного кодування. Однак покращена LZMA-можливість компресувати файли малого розміру полягає в його «просунутих алгоритмах зіставлення і вікон LZ.
Сьогодні в інтернеті використовують два широко використовуваних алгоритмів стиснення тексту HTTP: DEFLATE і GZIP. DEFLATE - зазвичай об'єднує дані, із застосуванням LZ77 кодування Хаффмана. GZIP – файл використовує DEFLATE всередині, поряд з деякими цікавими блокуваннями, евристикою фільтрації, заголовком і контрольною сумою. В цілому, додаткове блокування та евристика, використовують GZIP, дають якісні коефіцієнти стиснення, ніж просто один DEFLATE. Протоколи даних наступного покоління - SPDY і HTTP2.0 підтримують стиснення заголовків з допомогою GZIP, тому більша частина веб-стека буде використовувати і в майбутньому. Більшість розробників просто завантажують незжатий контент і покладаються на веб-сервер для "зменшення" даних на льоту. Це дає відмінні результати і простий у використанні алгоритм стиснення графічних зображень. За замовчуванням на багатьох серверах встановлений GZIP з рівнем 6 найбільший рівень якого дорівнює 9. Це зроблено навмисно, що дозволяє серверам компресувати дані швидше за рахунок більшого вихідного файлу. Формати BZIP2 і LZMA, що створюють більш компактні форми чим GZIP, які при цьому розпаковуються швидше. LZMA можна вважати далеким родичем GZIP. Обидва вони починаються з популярного словника LZ, за яким слід система статистичного кодування. Однак покращена LZMA-можливість компресувати файли малого розміру полягає в його «просунутих алгоритмах зіставлення і вікон LZ.  Для якісного стиснення виконують двоетапний процес: етап мінімізації; етап без втрат. Минификация - це скорочення розміру даних таким чином, щоб вони могли використовуватися без обробки, стираючи у файлі багато непотрібного, не змінюючи їх синтаксично. Так, безпечно видалити більшу частину прогалин з Jscript, знижуючи розмір без змін синтаксису. Минификация виконується під час процесу складання. Або як ручний крок, або як частина автоматизованої ланцюжка складання. Є багато програм, які виконують основні алгоритми стиснення, серед них: Winzip - це формат зберігання без втрат, широко використовуваний для документів, зображень або додатків. Це досить проста програма, яка стискає кожен з файлів в окремо, що дозволяє відновлювати кожен без необхідності читати інші. Тим самим підвищуючи продуктивність процесу. 7zip - Безкоштовний менеджер для дуже потужного і простого алгоритму стиснення інформації. Завдяки формату файлів 7z, який покращує стандарт ZIP на 50%. Він підтримує інші найбільш поширені формати, такі як RAR, ZIP, CAB, GZIP і ARJ, тому не створює проблем для використання з будь-яким стисненим файлом і інтегрується з контекстним меню в Windows. GZIP - це один з найвідоміших компресорів, призначених для Linux. Враховуючи успіх на цій платформі, його доопрацювали для Windows. Одним з основних переваг gzip є те, що він використовує алгоритм DEFLATE (комбінація кодування LZ77 та Хаффмана). WinRAR - Компресорна програма і багатофункціональний декомпрессор даних. Це незамінний інструмент для економії місця на диску і часу передачі при відправлення та отримання файлів через інтернет або при резервному копіюванні. Він служить для стиснення всіх типів документів або програм, щоб вони займали менше місця на диску і могли швидше зберігатися або передаватися по мережі. Це перший компресор, який реалізує 64-бітове управління файлами, що дозволяє обробляти великі обсяги, обмежені тільки операційною системою.
Для якісного стиснення виконують двоетапний процес: етап мінімізації; етап без втрат. Минификация - це скорочення розміру даних таким чином, щоб вони могли використовуватися без обробки, стираючи у файлі багато непотрібного, не змінюючи їх синтаксично. Так, безпечно видалити більшу частину прогалин з Jscript, знижуючи розмір без змін синтаксису. Минификация виконується під час процесу складання. Або як ручний крок, або як частина автоматизованої ланцюжка складання. Є багато програм, які виконують основні алгоритми стиснення, серед них: Winzip - це формат зберігання без втрат, широко використовуваний для документів, зображень або додатків. Це досить проста програма, яка стискає кожен з файлів в окремо, що дозволяє відновлювати кожен без необхідності читати інші. Тим самим підвищуючи продуктивність процесу. 7zip - Безкоштовний менеджер для дуже потужного і простого алгоритму стиснення інформації. Завдяки формату файлів 7z, який покращує стандарт ZIP на 50%. Він підтримує інші найбільш поширені формати, такі як RAR, ZIP, CAB, GZIP і ARJ, тому не створює проблем для використання з будь-яким стисненим файлом і інтегрується з контекстним меню в Windows. GZIP - це один з найвідоміших компресорів, призначених для Linux. Враховуючи успіх на цій платформі, його доопрацювали для Windows. Одним з основних переваг gzip є те, що він використовує алгоритм DEFLATE (комбінація кодування LZ77 та Хаффмана). WinRAR - Компресорна програма і багатофункціональний декомпрессор даних. Це незамінний інструмент для економії місця на диску і часу передачі при відправлення та отримання файлів через інтернет або при резервному копіюванні. Він служить для стиснення всіх типів документів або програм, щоб вони займали менше місця на диску і могли швидше зберігатися або передаватися по мережі. Це перший компресор, який реалізує 64-бітове управління файлами, що дозволяє обробляти великі обсяги, обмежені тільки операційною системою.  Існує багато минификаторов CSS. Деякі з доступних варіантів включають: онлайн CSS Minifier; freeformatter.com/css-minifier; cleancss.com/css-minify; cnvyr.io; minifier.org; css-minifier.com. Основна відмінність між цими інструментами залежить від того, наскільки глибокі процеси минификации. Так, спрощена оптимізація фільтрує текст, щоб прибрати зайві прогалини і масиви. Розвинена оптимізація передбачає заміну «AntiqueWhite» на « # FAEBD7 », оскільки шістнадцяткова форма у файлі коротше, і примусове використання символу нижнього GZIP-регістра. Більш агресивні способи CSS економлять місце, але можуть порушити вимоги CSS. Таким чином, більшість з них не мають можливості бути автоматизованими, і розробники роблять вибір між розміром або ступенем ризику. Насправді, є нова тенденція створення інших версій з мов CSS, щоб більш ефективно допомогти автору коду в якості додаткової переваги, що дозволяє компілятору виробляти менший код CSS.
Існує багато минификаторов CSS. Деякі з доступних варіантів включають: онлайн CSS Minifier; freeformatter.com/css-minifier; cleancss.com/css-minify; cnvyr.io; minifier.org; css-minifier.com. Основна відмінність між цими інструментами залежить від того, наскільки глибокі процеси минификации. Так, спрощена оптимізація фільтрує текст, щоб прибрати зайві прогалини і масиви. Розвинена оптимізація передбачає заміну «AntiqueWhite» на « # FAEBD7 », оскільки шістнадцяткова форма у файлі коротше, і примусове використання символу нижнього GZIP-регістра. Більш агресивні способи CSS економлять місце, але можуть порушити вимоги CSS. Таким чином, більшість з них не мають можливості бути автоматизованими, і розробники роблять вибір між розміром або ступенем ризику. Насправді, є нова тенденція створення інших версій з мов CSS, щоб більш ефективно допомогти автору коду в якості додаткової переваги, що дозволяє компілятору виробляти менший код CSS.  Основними перевагами стиснення є скорочення апаратних засобів зберігання, часу передачі даних та пропускної здатності зв'язку. Такий файл потребує меншого об'єму пам'яті, а використання методу призводить до зниження витрат на дискові або твердотільні накопичувачі. Він вимагає менше часу для передачі при низькій пропускній спроможності мережі. Основним недоліком компресії є вплив на продуктивність в результаті використання ресурсів ЦП і пам'яті для процесу і подальшої розпакування. Багато виробники розробили системи, щоб спробувати мінімізувати вплив ресурсномістких обчислень, пов'язаних зі стисненням. Якщо воно виконується до того як дані будуть записані на диск, система може розвантажити процес, щоб зберегти системні ресурси. Наприклад, IBM використовує окрему карту апаратного прискорення для обробки стиснення в деяких корпоративних системах зберігання. Якщо дані стискаються після їх запису на диск або після обробки, воно виконуватися у фоновому режимі, щоб зменшити вплив на продуктивність машини. Хоча стиск після обробки зменшує час відгуку для кожного вводу і виводу (I /O), воно все ще споживає пам'ять і цикли процесора і впливати на кількість операцій, які обробляє система зберігання. Крім того, оскільки дані спочатку повинні бути записані на диск або флеш-накопичувачі у стислому вигляді, економія фізичної пам'яті не так велика, як при вбудованому "зменшення". Майбутнє ніколи не визначено, але виходячи з поточних тенденцій, можна зробити деякі прогнози відносно того, що може статися з технологією стиснення даних. Алгоритми змішування контексту, такі як PAQ і його варіанти, почали набувати популярність, і вони мають тенденцію досягати найвищих коефіцієнтів "зменшення". Хоча зазвичай вони повільні. З експоненціальним збільшенням апаратної швидкості відповідно до закону Мура, процеси змішування контексту, ймовірно, будуть процвітати. Так як витрати на швидкість долаються за рахунок швидкого обладнання з-за високого ступеня стиснення. Алгоритм, який PAQ прагнув поліпшити, називається "Прогнозування шляхів часткового зіставлення". Або PPM. Нарешті, ланцюгової алгоритм Лемпеля-Зіва-Маркова (LZMA) незмінно демонструє чудовий компроміс між швидкістю і високим ступенем стиснення і, ймовірно, створить більше нових варіантів у майбутньому. Він буде лідирувати, оскільки вже прийнятий у багатьох конкуруючих форматів стиснення, наприклад, у програмі 7-Zip. Іншим потенційним розвитком є використання компресії за допомогою перерахування підрядків (CSE), яка являє собою перспективну технологію і поки не має багато програмних реалізацій.
Основними перевагами стиснення є скорочення апаратних засобів зберігання, часу передачі даних та пропускної здатності зв'язку. Такий файл потребує меншого об'єму пам'яті, а використання методу призводить до зниження витрат на дискові або твердотільні накопичувачі. Він вимагає менше часу для передачі при низькій пропускній спроможності мережі. Основним недоліком компресії є вплив на продуктивність в результаті використання ресурсів ЦП і пам'яті для процесу і подальшої розпакування. Багато виробники розробили системи, щоб спробувати мінімізувати вплив ресурсномістких обчислень, пов'язаних зі стисненням. Якщо воно виконується до того як дані будуть записані на диск, система може розвантажити процес, щоб зберегти системні ресурси. Наприклад, IBM використовує окрему карту апаратного прискорення для обробки стиснення в деяких корпоративних системах зберігання. Якщо дані стискаються після їх запису на диск або після обробки, воно виконуватися у фоновому режимі, щоб зменшити вплив на продуктивність машини. Хоча стиск після обробки зменшує час відгуку для кожного вводу і виводу (I /O), воно все ще споживає пам'ять і цикли процесора і впливати на кількість операцій, які обробляє система зберігання. Крім того, оскільки дані спочатку повинні бути записані на диск або флеш-накопичувачі у стислому вигляді, економія фізичної пам'яті не так велика, як при вбудованому "зменшення". Майбутнє ніколи не визначено, але виходячи з поточних тенденцій, можна зробити деякі прогнози відносно того, що може статися з технологією стиснення даних. Алгоритми змішування контексту, такі як PAQ і його варіанти, почали набувати популярність, і вони мають тенденцію досягати найвищих коефіцієнтів "зменшення". Хоча зазвичай вони повільні. З експоненціальним збільшенням апаратної швидкості відповідно до закону Мура, процеси змішування контексту, ймовірно, будуть процвітати. Так як витрати на швидкість долаються за рахунок швидкого обладнання з-за високого ступеня стиснення. Алгоритм, який PAQ прагнув поліпшити, називається "Прогнозування шляхів часткового зіставлення". Або PPM. Нарешті, ланцюгової алгоритм Лемпеля-Зіва-Маркова (LZMA) незмінно демонструє чудовий компроміс між швидкістю і високим ступенем стиснення і, ймовірно, створить більше нових варіантів у майбутньому. Він буде лідирувати, оскільки вже прийнятий у багатьох конкуруючих форматів стиснення, наприклад, у програмі 7-Zip. Іншим потенційним розвитком є використання компресії за допомогою перерахування підрядків (CSE), яка являє собою перспективну технологію і поки не має багато програмних реалізацій.
Історія виникнення процесу
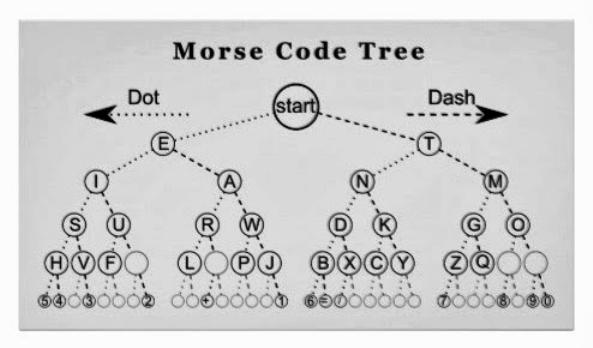
Тільки в 1970-х з появою інтернету і онлайн-сховищ, були реалізовані повноцінні алгоритми стиснення. Коди Хаффмана динамічно генерувалися на базі вхідної інформації. Ключова відмінність між кодування Шеннона-Фано і кодування Хаффмана полягає в тому, що в першому дерево ймовірності будувалося знизу вгору, створюючи неоптимальний результат, а в другому - зверху вниз. У 1977 році, Авраам Лемпель і Джейкоб Зів видали свій інноваційний метод LZ77 що використовує більш модернізований словник. У 1978 році, та ж команда авторів, видала вдосконалений алгоритм стиснення LZ78. Який використовує новий словник, аналізує вхідні дані і генерує статичні словник, а не динамічний, як у 77 версії.
Форми виконання компресії
Компресія виконується програмою, яка використовує формулу або алгоритм, що визначають, як зменшити розмір даних. Наприклад, уявити рядок бітів з меншою рядком 0 і 1 використовуючи словник для перетворень або формулу. Стиск може бути простим. Таким, наприклад, як видалення всіх непотрібних символів, вставки повторюваного коду для зазначення рядка повтору і заміна бітової рядка меншого розміру. Алгоритм стиснення файлів здатний зменшити текстовий файл до 50% або значно більше. Для передачі процес виконують в блоці передачі, включаючи дані заголовка. Коли інформація надсилається або приймається через інтернет, архівні за окремо або разом з іншими великими файлами, можуть передаватися в ZIP, GZIP або іншому "зменшеному форматі. Перевага алгоритмів стиснення: Значно зменшує обсяг пам'яті. При ступені стиснення 2:1 файл в 20 мегабайт (МБ) займе 10 МБ простору. В результаті адміністратори мережі витрачають менше грошей і часу на зберігання баз даних. Оптимізує продуктивність резервного копіювання. Важливий метод скорочення даних. Практично будь-який файл може бути стиснутий, але важливо вибрати потрібну технологію під конкретний тип файлу. Інакше файли можуть бути зменшені", але при цьому загальний розмір не зміниться. Застосовують методи двох видів - алгоритми стиснення без втрат і з втратами. Перший дозволяє відновити файли в початковий стан без втрати одного біта інформації при стислому файлі. Другий - це типовий підхід до виконуваним файлам, текстовим і електронних таблиць, де втрата слів або чисел призведе до зміни інформації.Стиснення з втратами назавжди видаляє біти даних, які є надлишковими, неважливими або непомітними. Воно корисно з графікою, аудіо, відео та зображеннями, де видалення деяких бітів практично не чинить помітного впливу на подання контенту.
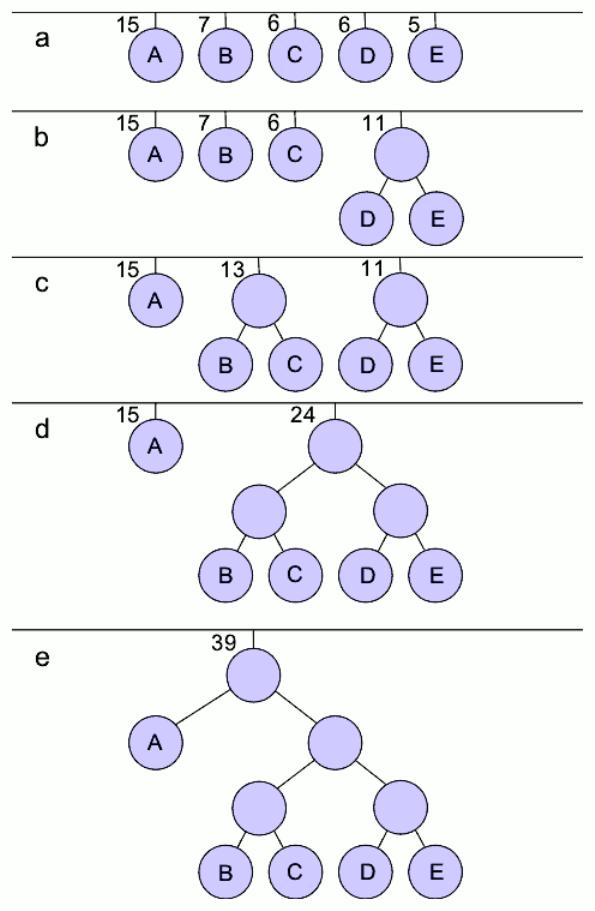
Алгоритм стиснення Хаффмана
Цей процес, який можна використовувати для "зменшення" або шифрування. Він заснований на призначення кодів різної довжини бітів відповідному кожному повторюваного символу, чим більше таких повторів, тим вище ступінь стиснення. Щоб відновити вихідний файл, необхідно знати призначений код і його довжину в бітах. Аналогічним чином, використовують програму для шифрування файлів. Порядок створення алгоритми стиснення даних: Прораховують, скільки разів кожен символ повторюється у файлі для "зменшення". Створюють зв'язаний список з інформацією про символи і частотах. Виконують сортування списку від найменшого до найбільшого в залежності від частоти. Перетворять кожен елемент списку в дерево. Об'єднують дерева в одну, при цьому перші два утворюють нове. Додають частоти кожної гілки в новий елемент дерева. Вставляють нове в потрібне місце в списку, відповідно до суми отриманих частот. Призначають новий двійковий код кожного символу. Якщо береться нульова гілку, до коду додається нуль, а якщо перша гілка, додається одиниця. Файл перекодовується у відповідності з новими кодами. Наприклад характеристики алгоритмів стиснення для короткого тексту:"ata la jaca a la estaca" Підраховують, скільки разів з'являється кожен символ і складають зв'язаний список:" (5), a (9), c (2), e (1), j (1), l (2), s (1), t (2) Замовляють по частоті від нижчої до вищої: e (1), j (1), s (1), c (2), l (2), t (2), " (5), a (9)

01110010
11010101
11111011
00010010
11010101
11110111
10111001
10000000
0x72
0xd5
0xFB
0x12
0xd5
0xF7
0xB9
0x80
Всього вісім байтів, а вихідний текст був 23.
Демонстрація бібліотеки LZ77
Алгоритм LZ77 розглянемо на прикладі тексту«howtogeek». Якщо повторити його три рази, то він змінить його наступним чином.

Це, звичайно, досить екстремальний приклад, але наочно демонструє властивості алгоритмів стиснення. У загальній практиці він становить 30-40% з текстовим форматом ZIP. Алгоритм LZ77 застосовується до всіх двійковим даними, а не тільки до тексту, хоча останній легше стиснути через повторюваних слів.
Дискретне косинусне перетворення зображень
Стиснення відео та аудіо працює зовсім по-іншому. На відміну від тексту, де виконують алгоритми стиснення без втрат, і дані не будуть втрачені, із зображеннями виконують "зменшення" з втратами, і чим більше %, тим більше втрат. Це призводить до тих жахливо виглядає JPEG-файлів, які люди завантажували, обмінювали та робили скріншоти по кілька разів. Більшість картинок, фото і іншого зберігають список чисел, кожен з яких представляє один піксель. JPEG зберігає їх, використовуючи алгоритм стиснення зображень, званим дискретним косинусным перетворенням. Воно являє собою сукупність синусоїдальних хвиль, що складаються разом з різною інтенсивністю. Цей метод використовує 64 різних рівняння, потім кодування Хаффмана, щоб ще більше зменшити розмір файлу. Подібний алгоритм стиснення зображень дає шалено високу ступінь стиснення, і зменшує його від декількох мегабайт до декількох кілобайт, в залежності від необхідної якості. Більшість фото стискуються, щоб заощадити час завантаження, особливо для мобільних користувачів з поганим передачею даних.Відео працює трохи інакше, ніж зображення. Зазвичай алгоритми стиснення графічної інформації використовують тим, що називається «міжкадрових стисненням», яке обчислює зміни між кожним кадром і зберігає їх. Так, наприклад, якщо є відносно нерухомий знімок, який займає декілька секунд відео, він буде "зменшений" в один. Межкадровое стиснення забезпечує цифрове телебачення і веб-відео. Без нього відео важило сотнями гігабайт, що більше середнього розміру жорсткого диска в 2005 році. Стиснення аудіо працює дуже схоже на стиснення тексту і зображень. Якщо JPEG видаляє деталі зображення, яке невидимі людським оком, стиснення звуку робить, те ж саме для звуків. MP3 використовує бітрейт, в діапазоні від нижнього рівня 48 і 96 кбіт/с (нижня межа) до 128 і 240 кбіт/с (досить хороший) до 320 кбіт/с (високоякісний звук), і почути різницю можна тільки з виключно хорошими навушниками. Існують кодеки стиснення без втрат для звуку, основним з яких є FLAC і використовує кодування LZ77 для передачі звуку без втрат.
Формати "зменшення" тексту
Діапазон бібліотек для тексту в основному складається з алгоритму стиснення даних без втрат, за винятком крайніх випадків для даних з плаваючою комою. Більшість компресорних кодеків включають "зменшення" LZ77 Хаффмана і Арифметичне кодування. Вони застосовуються після інших інструментів, щоб вичавити ще кілька процентних точок стиснення.

Схеми HTTP: DEFLATE і GZIP
Попередня обробка документу

Минификаторы CSS

Плюси і мінуси стиснення

Цікаво по темі
Ветеран серед архіваторів: коротко про "7-Зіп"
Одні з найстаріших типів додатків для ПК - архіватори. Вони досі не втратили своєї актуальності. Потреба створення архівів з подальшою передачею

Як створити gif з відео
Вам потрібно терміново відправити певні зображення у вигляді анімованих картинок іншій людині, а у вас під рукою тільки інтернет і "Фотошоп", яким ви
Від чого залежить ступінь стиснення файлу? Поняття та основні аспекти
Більшість користувачів знає, що іноді для зменшення розміру вихідних файлів з метою підвищення зручності їх зберігання чи відправлення, наприклад, по

Формат Lossless - що таке? Стиснення без втрат
Справжні меломани вже знають, що музика у звичному форматі МР3 не може порадувати деталізацією і правдивістю звучання. Особливо всі огріхи цього

Глибина кодування звуку - це що таке? Визначення, формула
Звук існує як аналогова хвильова форма. Сегмент цифрового звуку апроксимує цю аналогову хвилю, сэмплирует її амплітуду з досить високою швидкістю,