Robots.txt Disallow: як створити, особливості та рекомендації
Потрапляючи на курси з SEO-просування, новачки зустрічаються з великою кількістю зрозумілих і не дуже термінів. У всьому цьому розібратися не так вже й просто, особливо якщо спочатку погано пояснили або втратили якийсь з моментів. Розглянемо значення у файлі robots.txt Disallow, для чого потрібен цей документ, як його створити і працювати з ним. 
Але на сайтах є і така інформація, яка не обов'язкова для статистики. Наприклад, сторінка «Про компанії» або «Контакти». Все це необов'язково для індексації, а в деяких випадках небажано, оскільки може спотворити статистичні дані. Щоб цього всього не було, краще закривати ці сторінки від робота. Саме для цього і потрібна команда у файлі robots.txt Disallow.
 Файл дає швидкий доступ ПС до будь-якій сторінці, показує останні зміни, частоту та важливість їх. За цими критеріями робот найбільш правильно сканує сайт. Але важливо розуміти, що наявність такого файлу не дає впевненості в тому, що всі сторінки будуть проіндексовані. Він є більше підказкою на шляху до цього процесу.
Файл дає швидкий доступ ПС до будь-якій сторінці, показує останні зміни, частоту та важливість їх. За цими критеріями робот найбільш правильно сканує сайт. Але важливо розуміти, що наявність такого файлу не дає впевненості в тому, що всі сторінки будуть проіндексовані. Він є більше підказкою на шляху до цього процесу.
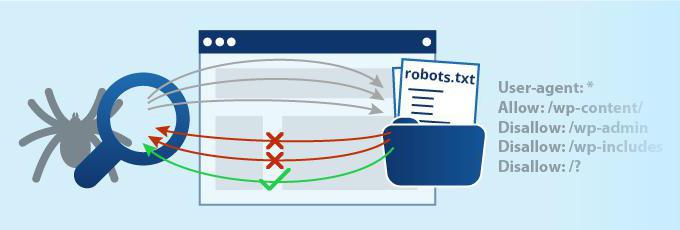
Також файл використовують, щоб приховати від очей пошукової системи: Сторінки з особистими даними відвідувачів. Сторінки, на яких є форми відправки даних і т. п. Сайти-дзеркала. Сторінки з результатами пошуку.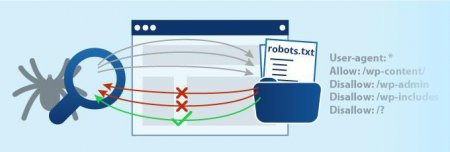 Якщо ви вказали в robots.txt Disallow для конкретної сторінки, є шанс, що вона все ж з'явиться в пошуковій видачі. Такий варіант може статися, якщо на одному з зовнішніх ресурсів або всередині вашого сайту розміщено посилання на сторінку.
Якщо ви вказали в robots.txt Disallow для конкретної сторінки, є шанс, що вона все ж з'явиться в пошуковій видачі. Такий варіант може статися, якщо на одному з зовнішніх ресурсів або всередині вашого сайту розміщено посилання на сторінку. 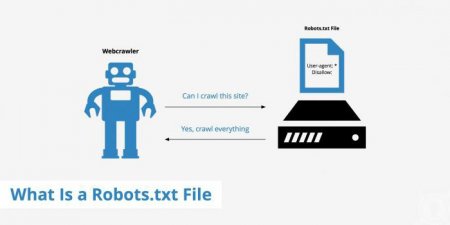
Повний список імен ботів можна знайти в інтернеті. Він дуже довгий, тому, якщо вам потрібні вказівки для певних сервісів Google чи Yandex, доведеться вказувати конкретні імена.
 Універсальний набір директив дозволяє відкривати вміст сайту для індексації. Тут є прописка хоста і вказується карта сайту. Вона дає можливість роботам завжди відвідувати сторінки, обов'язкові для сканування. Заковика в тому, що дані можуть змінюватись в залежності від системи, на якій стоїть ваш ресурс. Тому правила потрібно підбирати, дивлячись на тип сайту і CMS. Якщо ви не впевнені, що створений вами файл правильний, можна перевірити в інструменті вебмастера Google і "Яндекс".
Універсальний набір директив дозволяє відкривати вміст сайту для індексації. Тут є прописка хоста і вказується карта сайту. Вона дає можливість роботам завжди відвідувати сторінки, обов'язкові для сканування. Заковика в тому, що дані можуть змінюватись в залежності від системи, на якій стоїть ваш ресурс. Тому правила потрібно підбирати, дивлячись на тип сайту і CMS. Якщо ви не впевнені, що створений вами файл правильний, можна перевірити в інструменті вебмастера Google і "Яндекс".  Поле User-agent має бути заповнено завжди. Не залишайте цю директиву без команди. Знову повертаючись до хосту, пам'ятайте, що якщо сайт використовує протокол HTTP, то вказувати в команді його не потрібно. Тільки якщо це розширений варіант HTTPS. Не можна залишати директиву Disallow без значення. Якщо вона вам не потрібна, просто не вказуйте її.
Поле User-agent має бути заповнено завжди. Не залишайте цю директиву без команди. Знову повертаючись до хосту, пам'ятайте, що якщо сайт використовує протокол HTTP, то вказувати в команді його не потрібно. Тільки якщо це розширений варіант HTTPS. Не можна залишати директиву Disallow без значення. Якщо вона вам не потрібна, просто не вказуйте її.
Простими словами
Щоб не «годувати» читача складними поясненнями, які зазвичай зустрічаються на спеціалізованих сайтах, краще пояснити все «на пальцях». Пошуковий робот приходить на ваш сайт і індексує сторінки. Після ви дивитеся звіти, які вказують на проблеми, помилки тощо
Але на сайтах є і така інформація, яка не обов'язкова для статистики. Наприклад, сторінка «Про компанії» або «Контакти». Все це необов'язково для індексації, а в деяких випадках небажано, оскільки може спотворити статистичні дані. Щоб цього всього не було, краще закривати ці сторінки від робота. Саме для цього і потрібна команда у файлі robots.txt Disallow.
Стандарт
Цей документ завжди є на сайтах. Його створенням займаються розробники і програмісти. Іноді це можуть робити і власники ресурсу, особливо, якщо він невеликий. У цьому випадку робота з ним не займає багато часу. Robots.txt називають стандартом виключень для пошукового робота. Він представлений документом, у якому прописують основні обмеження. Документ поміщають в корінь ресурсу. При цьому так, щоб його можна було знайти по шляху «/robots.txt». Якщо ресурс має кілька піддоменів, то цей файлик поміщається в корінь кожного з них. Стандарт безперервно пов'язаний з іншим – Sitemaps.Карта сайту
Щоб розуміти повну картину того, про що йде мова, пару слів про Sitemaps. Це файл, написаний мовою XML. Він зберігає всі дані про ресурс для ПС. За документом можна дізнатися про веб-сторінках, індексованих роботами.
Використання
Правильний файл robots.txt використовується добровільно. Сам стандарт з'явився ще в 1994 році. Його прийняв консорціум W3C. З того моменту став використовуватися майже у всіх пошукових машин. Він потрібний для «дозованої» коригування сканування ресурсу пошуковим роботом. Файл містить комплекс інструкцій, які використовують ПС. Завдяки набору інструментів легко встановлюють файли, сторінки, каталоги, які не можна індексувати. Robots.txt вказує і на такі файли, які потрібно перевірити відразу.Для чого?
Незважаючи на те, що файл дійсно можна використовувати добровільно, його створюють практично всі сайти. Це потрібно для того, щоб упорядкувати роботу робота. Інакше він буде перевіряти всі сторінки у випадковій послідовності, і крім того, що може пропускати деякі сторінки, створює вагому навантаження на ресурс.Також файл використовують, щоб приховати від очей пошукової системи: Сторінки з особистими даними відвідувачів. Сторінки, на яких є форми відправки даних і т. п. Сайти-дзеркала. Сторінки з результатами пошуку.
Директиви
Говорячи про заборону для пошукової системи, часто використовують поняття «директиви». Цей термін відомий всім програмістам. Він часто замінюється синонімом «вказівку» і використовується разом з «командами». Іноді може бути представлений набором конструкцій мови програмування. Директива Disallow в robots.txt одна з найпоширеніших, але не єдина. Крім неї є ще кілька, які відповідають за певні вказівки. Приміром, є User agent, який показує на роботів пошукової системи. Allow - це протилежна команда Disallow. Вона вказує на дозвіл для сканування деяких сторінок. Далі розглянемо докладніше основні команди.Візитка
Природно, у файлі robots.txt User agent Disallow не єдині директиви, але одні з найпоширеніших. Саме з них складається більшість файлів для невеликих ресурсів. Візиткою для будь-якої системи все ж вважається команда User agent. Це правило створено для того, щоб вказати на роботів, які поглядають інструкції, які будуть написані далі в документі. Зараз існує 300 пошукових роботів. Якщо ви хочете, щоб кожен з них слідував певним зазначенням, не слід їх переписувати все навряд. Досить буде вказати «User-agent: *». «Зірочка» в цьому випадку покаже систем, що такі правила розраховані на всіх пошукові системи. Якщо ж ви створюєте вказівки для Google, тоді потрібно вказати ім'я робота. У цьому випадку використовуйте Googlebot. Якщо в документі буде зазначено тільки це ім'я, тоді інші пошукові системи не будуть сприймати команди файлу robots.txt: Disallow, Allow і т. д. Вони будуть вважати, що документ порожній, і для них немає ніяких інструкцій.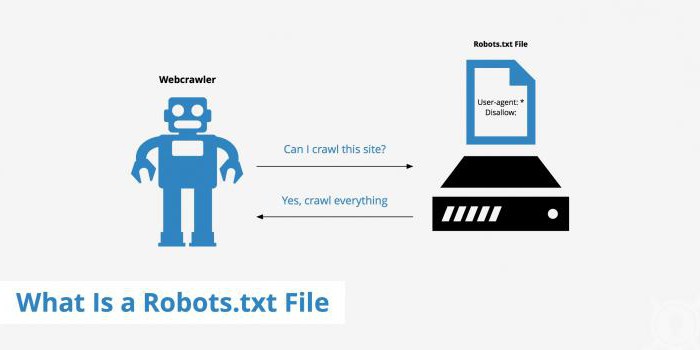
Повний список імен ботів можна знайти в інтернеті. Він дуже довгий, тому, якщо вам потрібні вказівки для певних сервісів Google чи Yandex, доведеться вказувати конкретні імена.
Заборона
Про наступну команді ми вже говорили багато разів. Disallow якраз і вказує на те, яка інформація не повинна зчитуватися роботом. Якщо ви хочете показати пошуковим системам весь свій контент, тоді достатньо написати «Disallow:». Так роботи будуть сканувати всі сторінки вашого ресурсу. Повна заборона індексації robots.txt «Disallow: /». Якщо ви напишіть так, тоді роботи не будуть сканувати ресурс взагалі. Зазвичай це робиться на початкових етапах, при підготовці до запуску проекту, експериментах і т. д. Якщо сайт вже готовий показати себе, тоді змініть це значення, щоб користувачі могли познайомитися з ним. Взагалі команда універсальна. Вона може заблокувати певні елементи. Наприклад, папку, командою «Disallow: /papka/», може заборонити для сканування посилання на файл або документи певного дозволу.Дозвіл
Щоб дозволити роботу переглядати певні сторінки, файли або каталоги, використовують директиву Allow. Іноді команда потрібна для того, щоб робот відвідав файли з певного розділу. Приміром, якщо це інтернет-магазин, можна вказати каталог. Інші сторінки будуть просканированы. Але пам'ятайте, що для початку потрібно заборонити сайту переглядати весь контент, а після вказати команду Allow з відкритими сторінками.
Дзеркала
Ще одна директива Host. Її використовують не всі веб-майстри. Вона потрібна в тому випадку, якщо ваш ресурс має дзеркала. Тоді це правило обов'язкове, оскільки вказує роботу "Яндекса" на те, яке з дзеркал є головним, і яке потрібно сканувати. Система не збивається самостійно і легко знаходить потрібний ресурс за інструкціями, які описані в robots.txt. У файлику сам сайт прописується без вказівки «http://», але тільки в тому випадку, якщо він працює на HTTP. Якщо ж він використовує протокол HTTPS, тоді вказує цю приставку. Наприклад, «Host: site.com» якщо HTTP, або «Host: https://site.com» у випадку з HTTPS.Навігатор
Про Sitemap ми вже говорили, але як про окремому файлі. Дивлячись на правила написання robots.txt з прикладами, бачимо і використання подібної команди. У файлі вказують «Sitemap: http://site.com/sitemap.xml». Це робиться для того, щоб робот перевірив всі сторінки, які вказані на карті сайту за адресою. Кожен раз повертаючись, робот буде переглядати нові оновлення, зміни, які були внесені і швидше відправляти дані в пошукову систему.Додаткові команди
Це були основні директиви, які вказують на важливі і потрібні команди. Є і менш корисні, і не завжди застосовуються вказівки. Приміром, Crawl-delay задає період, який буде використовуватися між завантаженнями сторінок. Це потрібно для слабких серверів, щоб не «покласти» їх навалою роботів. Для визначення параметра використовуються секунди. Clean-param допомагає уникнути дублювання контенту, який знаходиться на різних динамічних адреси. Вони виникають у тому випадку, якщо існує функція сортування. Така команда буде виглядати так: «Clean-param: ref /catalog/get_product.com».Універсальний
Якщо ви не знаєте, як створити правильний robots.txt – не страшно. Крім вказівок, є універсальні варіанти цього файлу. Їх можна розмістити практично на будь-якому сайті. Винятком може стати тільки великий ресурс. Але в цьому випадку про файлі повинні знати професіонали і займатися їм спеціальні люди.Помилки
Якщо ви розумієте, що значить Disallow в robots.txt це не дає гарантії того, що ви не помилитеся при створенні документа. Існує низка типових проблем, які виникають у недосвідчених користувачів. Часто плутають значення директиви. Це може бути пов'язано і з нерозумінням, і з незнанням вказівок. Можливо, ви просто недогледів і за неуважність переплутав. Приміром, можуть використовувати для User-agent значення «/», а для Disallow ім'я робота. Перерахування – це ще одна поширена помилка. Деякі користувачі вважають, що перерахування заборонених сторінок, файлів або папок потрібно вказувати поспіль в один ряд. На ділі ж для кожної забороненої або дозволеної посилання, файлу і папки потрібно писати команду знову і з нового рядка. Помилки можуть бути викликані неправильним назвою самого файлу. Пам'ятайте, що він називається «robots.txt». Використовуйте для назви нижній регістр, без варіацій типу «Robots.txt» або «ROBOTS.txt».
Висновки
Резюмуючи, варто сказати, що robots.txt – це стандарт, який вимагає точності. Якщо ви з ним жодного разу не стикалися, то на перших етапах створення у вас буде виникати багато питань. Краще віддати цю роботу веб-майстрам, оскільки вони працюють з документом весь час. До того ж можуть траплятися деякі зміни в сприйнятті директив пошуковими системами. Якщо ж у вас невеликий сайт - маленький інтернет-магазин або блозі - тоді достатньо буде вивчити це питання і взяти один з універсальних прикладів.Цікаво по темі
Як створити Sitemap: докладна інструкція для оптимізатора
Чому багато оптимізаторів в першу чергу перевіряють наявність і структуру карти сайту? Справа в тому...

Індексація сайту в "Яндекс": як зробити сайт "смачним" для пошуковика?
Як привернути увагу роботів "Яндекса", скільки чекати і які інструменти використовувати? Що заважає вашому проекту успішно стартувати? Дізнайтеся все
12 способів дізнатися власника домену або сайту
Якщо вам необхідно дізнатися, хто власник доменного імені певного сайту, то ми пропонуємо використати для цього 12 способів, які можуть допомогти вам

Htaccess (кодування): налаштування, приклади використання
Кожна людина, займаючись серфінгом в інтернеті, набредал на такі веб-сторінки і сайти, які некоректно відображаються. Наприклад, відкривши

Індексація сайту в пошукових системах. Як відбувається індексування сайту в "Яндекс" і "Гугл"
Ви бажаєте, щоб ваш сайт відображався у запитах результатів пошуковиків? Тоді він повинен бути оброблений пошуковими системами «Рамблер», «Яндекс»,

Що таке пошуковий робот? Функції пошукового робота "Яндекса" і Google
Щодня в інтернеті з'являється величезна кількість нових матеріалів: створюються сайти, оновлюються старі веб-сторінки завантажуються фотографії і