Що таке потужність алфавіту
Алфавітом в інформатиці називається система знаків, за допомогою якої можна подати інформаційне повідомлення. Щоб зрозуміти сутність цього визначення, наведемо трохи додаткових теоретичних фактів: Будь-які повідомлення складаються з алфавіту. Наприклад, ця стаття - повідомлення. Тоді вона складається з символів російського алфавіту. Під символом ми можемо розуміти мінімально значущу частку алфавіту. Також неподільні частинки називають атомами. Символами в російському алфавіті є "а", "б", "в", і так далі. В теорії, алфавітом необов'язково бути закодованим як-небудь. Наприклад, в друкованій книзі символи алфавіту означають самі себе, значить, не мають будь-якого кодування.  Але на практиці ми маємо наступне: комп'ютер не розуміє, що таке літери. Тому для передачі інформаційного повідомлення, його спочатку потрібно закодувати зрозумілим комп'ютера мовою. Для того щоб рухатися далі, необхідно ввести додаткові терміни.
Але на практиці ми маємо наступне: комп'ютер не розуміє, що таке літери. Тому для передачі інформаційного повідомлення, його спочатку потрібно закодувати зрозумілим комп'ютера мовою. Для того щоб рухатися далі, необхідно ввести додаткові терміни.
M = 2 i Ця формула в загальному вигляді визначає зв'язок між кількістю рівноймовірно подій "M" і кількістю інформації "i".
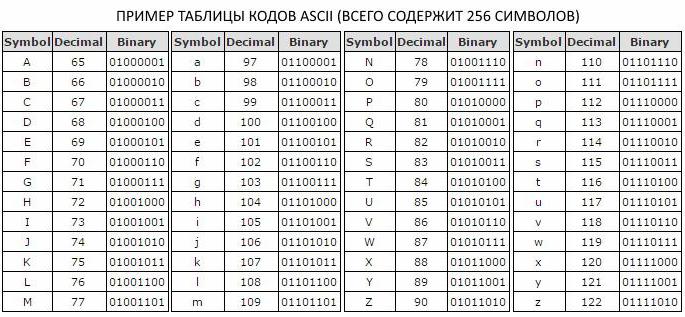
Так як в алфавіті потужністю 256 біт для позначення одного символа відводиться вісім двійкових розрядів, було вирішено ввести додаткову міру інформації - байт. Один байт містить один символ кодової таблиці ASCII і містить у собі вісім біт.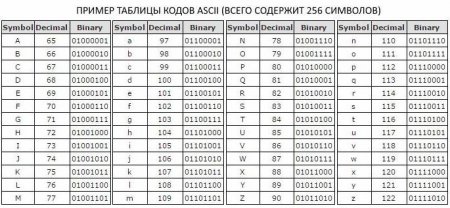
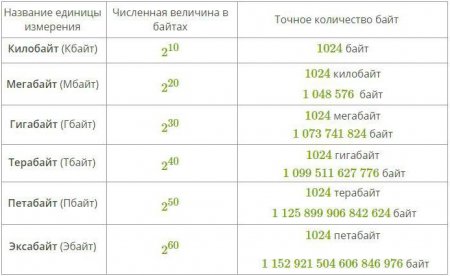 Багато люди, що вивчали фізику заперечать, що раціонально було б використовувати класичні приставки для позначення одиниць інформації (на кшталт кіло - і мега-), але насправді це не зовсім коректно, адже такі префікси до величин позначають множення на ту чи іншу ступінь числа десять, коли в інформатиці скрізь використовується двійкова система вимірювань.
Багато люди, що вивчали фізику заперечать, що раціонально було б використовувати класичні приставки для позначення одиниць інформації (на кшталт кіло - і мега-), але насправді це не зовсім коректно, адже такі префікси до величин позначають множення на ту чи іншу ступінь числа десять, коли в інформатиці скрізь використовується двійкова система вимірювань.
 Припустимо, що ми маємо текст, який містить K символів. Тоді, використовуючи алфавітний підхід, можна обчислити обсяг інформації V, який в ньому міститься. Він буде дорівнює добутку потужності алфавіту на інформаційний вага одного символу в ньому. За формулою Хартлі ми знаємо, як обчислити обсяг інформації через двійковий логарифм. Припустивши, що кількість знаків алфавіту дорівнює N і кількість знаків у записі інформаційного повідомлення дорівнює K, отримаємо таку формулу для обчислення інформаційного обсягу повідомлення: V = K ? log 2 N Алфавітний підхід свідчить про те, що інформаційний обсяг буде залежати тільки від потужності алфавіту та розміру повідомлень (тобто кількості символів в ньому), але ніяк не буде пов'язане зі смисловим змістом для людини.
Припустимо, що ми маємо текст, який містить K символів. Тоді, використовуючи алфавітний підхід, можна обчислити обсяг інформації V, який в ньому міститься. Він буде дорівнює добутку потужності алфавіту на інформаційний вага одного символу в ньому. За формулою Хартлі ми знаємо, як обчислити обсяг інформації через двійковий логарифм. Припустивши, що кількість знаків алфавіту дорівнює N і кількість знаків у записі інформаційного повідомлення дорівнює K, отримаємо таку формулу для обчислення інформаційного обсягу повідомлення: V = K ? log 2 N Алфавітний підхід свідчить про те, що інформаційний обсяг буде залежати тільки від потужності алфавіту та розміру повідомлень (тобто кількості символів в ньому), але ніяк не буде пов'язане зі смисловим змістом для людини.
 Таким чином, алфавіт потужністю 256 символів несе в собі лише 8 біт інформації, що в інформатиці називають одним байтом. Байт описує 1 символ таблиці ASCII, що, якщо замислитися, зовсім не багато.
Таким чином, алфавіт потужністю 256 символів несе в собі лише 8 біт інформації, що в інформатиці називають одним байтом. Байт описує 1 символ таблиці ASCII, що, якщо замислитися, зовсім не багато.  Але щоб уявити такі немислимі обсяги даних, необхідно чітко розуміти, що все складається з маленьких деталей. Необхідно розуміти, чому дорівнює потужність алфавіту (256) і скільки біт містить 1 байт інформації (як ви пам'ятаєте, 8).
Але щоб уявити такі немислимі обсяги даних, необхідно чітко розуміти, що все складається з маленьких деталей. Необхідно розуміти, чому дорівнює потужність алфавіту (256) і скільки біт містить 1 байт інформації (як ви пам'ятаєте, 8).

Що таке потужність алфавіту
Під потужністю алфавіту ми маємо на увазі загальне кількість символів в ньому. Для того щоб дізнатися, яка потужність алфавіту, необхідно просто порахувати кількість символів в ньому. Давайте розбиратися. Для російського алфавіту потужність алфавіту дорівнює 33 або ж 32 символів, якщо не використовувати "е". Давайте припустимо, що всі символи в нашому алфавіті зустрічаються з однаковою ймовірністю. Це припущення можна розуміти так: припустимо, у нас є мішок з підписаними кубиками. Кількість кубиків в ньому нескінченно, і кожний підписаний лише одним символом. Тоді при рівномірному розподілі, скільки б ми кубиків ні діставали з мішка, кількість кубиків з різними символами буде однаково, чи буде прагнути до цього при зростанні кількості кубиків, які ми дістаємо з мішка.Оцінка ваги інформаційних повідомлень
Майже сто років тому американський інженер Ральф Хартлі вивів формулу, за допомогою якої можна оцінювати кількість інформації в повідомленні. Його формула працює для рівноймовірно подій і виглядає так: i = log 2 M Де i - кількість неподільних інформаційних атомів (бітів) у повідомленні, "M" - потужність алфавіту. Ідемо далі. За допомогою математичних перетворень можемо визначити, що потужність алфавіту можна обчислити так:M = 2 i Ця формула в загальному вигляді визначає зв'язок між кількістю рівноймовірно подій "M" і кількістю інформації "i".
Розраховуємо потужність
Швидше за все, вам вже відомо з шкільного курсу інформатики, що в сучасних обчислювальних системах, побудованих на архітектурі фон Неймана, використовується двійкова система кодування інформації. Так кодуються як програми, так і дані. Для того щоб представити текст в обчислювальній системі, використовують рівномірний код з восьми розрядів. Рівномірним код тому вважається, що містить фіксований набір елементів - 0 і 1. Значення в такому коді задаються певним порядком цих елементів. За допомогою восьмирозрядного коду ми можемо закодувати повідомлення вагою 256 біт, адже по формулі Хартлі: M 8 =2 8 = 256 біт інформації. Така ситуація з кодуванням символів двійковим кодом склалася історично. Але теоретично ми могли б використовувати й інші алфавіти для представлення даних. Так, наприклад, в четырехзнаковом алфавіті у кожного символу був би вага не один, а два біта, в восьмизнаковом - 3 біта і так далі. Це розраховується за допомогою двійкового логарифму, який було наведено вище ( i = log 2 M ).Так як в алфавіті потужністю 256 біт для позначення одного символа відводиться вісім двійкових розрядів, було вирішено ввести додаткову міру інформації - байт. Один байт містить один символ кодової таблиці ASCII і містить у собі вісім біт.
Як вимірюють інформацію
Восьмібіт ва кодування текстових повідомлень, яка використовується у кодовій таблиці ASCII, дозволяє вмістити базовий набір символів латиниці і кирилиці у прописном і рядковому варіанті, цифри, символи знаків пунктуації та інші базові символи. Для того щоб вимірювати великі обсяги даних, використовують спеціальні приставки до слів байт і біт. Такі приставки наведені в таблиці нижче:
Правильні назви одиниць виміру даних
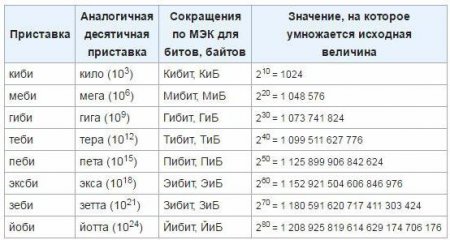
Для того щоб усунути некоректності і незручності, у березні 1999 року Міжнародною комісією в області електротехніки були затверджені нові приставки до одиниць, які використовуються для визначення обсягу інформації в електронній обчислювальній техніці. Такими приставками стали "меби", "киби", "гиби", "тебі", "эксби", "петі". Поки ці одиниці ще не прижилися, так що, швидше за все, необхідно час для запровадження цього стандарту і широкого застосування. Як здійснювати перехід від класичних одиниць до новоутвержденным, ви можете визначити по наступній таблиці: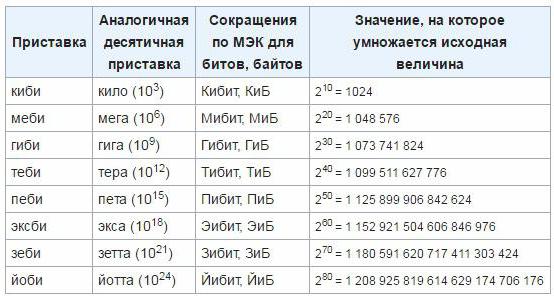
Приклади розрахунку потужності
На уроках інформатики часто дають завдання на знаходження потужності алфавіту, довжини повідомлення або інформаційного обсягу. Ось одна з таких завдань: "Текстовий файл займає 11 Кбайт дискового простору і містить 11264 символу. Визначте потужність алфавіту даного текстового файлу". Яким буде рішення, можна побачити на малюнку нижче.
Один байт - це багато чи мало?
Сучасні сховища даних зразок дата-центрів Google і Facebook містять не менше, ніж десятки петабайт інформації. Точна кількість даних, втім, важко буде підрахувати навіть їм самим, адже тоді потрібно буде зупинити всі процеси на серверах і закрити користувачам доступ до запису і редагування їх особистої інформації.
Цікаво по темі


Як вставити символ "гамма" в Word
Користувачі, які частенько стикаються з написанням різноманітних текстів, помічали, що символів на клавіатурі категорично не вистачає. Особливо
Кодування ASCII (American standard code for information interchange) - базова кодування тексту для латиниці
За даними Міжнародного Союзу електрозв'язку, в 2016 році Інтернетом з тією чи іншою регулярністю користувалося 35 мільярда людей. Більшість з них

Гб, Мб, Кб - це одиниці вимірювання інформації, а чим вони один від одного відрізняються?
Як визначити, скільки гігабайт в одному терабайте або скільки біт міститься в кілобайті? Навіть у досвідчених користувачів такі питання можуть
ASCII символи: опис, таблиця кодів і види
Кодування ASCII була розроблена понад півстоліття тому і протягом багатьох років була найпопулярнішою в світі. У цій статті розглянемо, як

Вільна таблиця символів Юнікоду
Unicode - це міжнародний стандарт кодування символів, що дозволяє одноманітно відображати тексти на ...