Вернуться назад
Распечатать
Читання файлу: функція file get content (PHP)
Формально конструкція file get content PHP схожа на file, але поміщає прочитане вміст в рядок, а не в масив рядків і дозволяє вказати зсув у файлі, з якого слід починати читання.  Звичайне читання допомогою fopen/fgets/fclose стає менш затребуваним. Зручніше прочитати вміст файлу або сторінки сайту цілком і потім робити з ним потрібні операції. Конструкція file get content PHP дозволяє створити більш ефективні продуктивні алгоритми обробки інформації.
Звичайне читання допомогою fopen/fgets/fclose стає менш затребуваним. Зручніше прочитати вміст файлу або сторінки сайту цілком і потім робити з ним потрібні операції. Конструкція file get content PHP дозволяє створити більш ефективні продуктивні алгоритми обробки інформації.  Тут $filename - ім'я файлу або URL сторінки, $use_include_path - дозволяє шукати файл в include path, $context - ресурс, створений конструкцією stream_context_create(), $offset - зміщення з якого починається читання, $maxlen - максимальну кількість даних, який потрібно прочитати.
Тут $filename - ім'я файлу або URL сторінки, $use_include_path - дозволяє шукати файл в include path, $context - ресурс, створений конструкцією stream_context_create(), $offset - зміщення з якого починається читання, $maxlen - максимальну кількість даних, який потрібно прочитати.
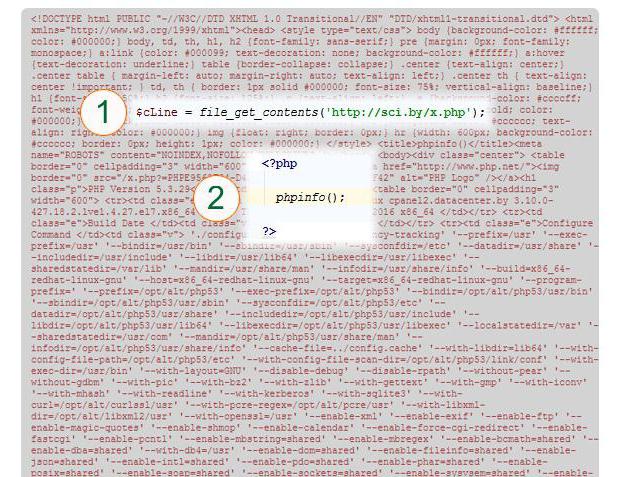
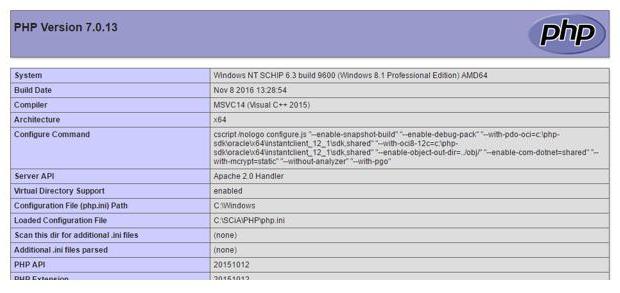
Зазвичай використовується більш простий варіант file get content PHP: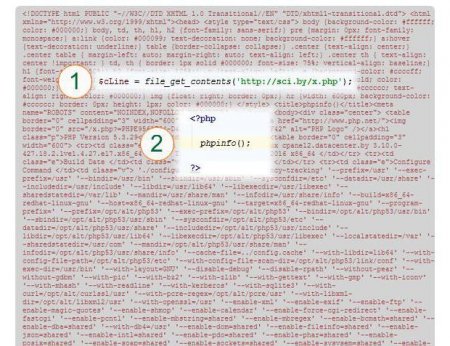 В даному прикладі вміст сторінки читається в змінну $cLine (1). Вказаний конкретний URL. Власне, сторінка (2) представлена конструкцією PHP phpinfo(), тобто, не читається текст з трьох рядків, а результат виконання цієї функції.
В даному прикладі вміст сторінки читається в змінну $cLine (1). Вказаний конкретний URL. Власне, сторінка (2) представлена конструкцією PHP phpinfo(), тобто, не читається текст з трьох рядків, а результат виконання цієї функції. 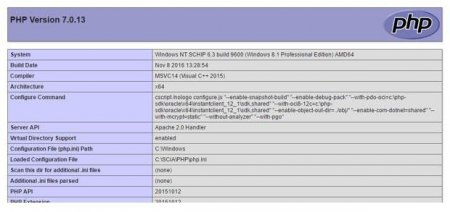 Як видно, результат являє собою повноцінну сторінку, у той час як конструкція PHP get file contents за адресою (http ) прочитала і записала внутрішній зміст цієї сторінки в змінну $cLine.
Як видно, результат являє собою повноцінну сторінку, у той час як конструкція PHP get file contents за адресою (http ) прочитала і записала внутрішній зміст цієї сторінки в змінну $cLine.  У звичайній практиці використання всіх параметрів, окрім $filename, не є популярним правилом. Однак значення, створюване конструкцією stream_context_create() і використовується в якості параметра $context, дозволяє писати досить-таки складні алгоритми отримання потрібної інформації. Різні файлові системи, обробники потоків (wrappers) вимагають різних настройок і опцій для опису контексту. Його можна створити за допомогою конструкцій stream_context_create (stream_context_set_option, stream_context_set_params).
У звичайній практиці використання всіх параметрів, окрім $filename, не є популярним правилом. Однак значення, створюване конструкцією stream_context_create() і використовується в якості параметра $context, дозволяє писати досить-таки складні алгоритми отримання потрібної інформації. Різні файлові системи, обробники потоків (wrappers) вимагають різних настройок і опцій для опису контексту. Його можна створити за допомогою конструкцій stream_context_create (stream_context_set_option, stream_context_set_params).
 Можна створити власний парсер сайтів, пошукову систему і писати програми розподіленої обробки інформації. Завдання актуальна, цікава і практична.
Можна створити власний парсер сайтів, пошукову систему і писати програми розподіленої обробки інформації. Завдання актуальна, цікава і практична.  Тут представлений складний документ, який використовується для тестування бібліотеки PHPOffice/PHPWord. Файл MS Word (*.docx), як відомо, являє собою zip-архів, всередині якого знаходиться інформація за стандартом Open XML. Як правило, файли документів досить великі, складні, але конструкція file get content PHP справляється з їх читанням без труднощів. Специфіка саме цього прикладу полягає в тому, що обробка документа чисто засобами бібліотеки PHPOffice/PHPWord не дозволяє отримати необхідні можливості, а послідовне читання файлу просто неможливо. В наведеному документі всі його елементи (слова, абзаци, формули, малюнки, елементи написання) описуються серіями тегів, причому деякі можуть бути представлені послідовністю вкладених один в одного об'єктів.
Тут представлений складний документ, який використовується для тестування бібліотеки PHPOffice/PHPWord. Файл MS Word (*.docx), як відомо, являє собою zip-архів, всередині якого знаходиться інформація за стандартом Open XML. Як правило, файли документів досить великі, складні, але конструкція file get content PHP справляється з їх читанням без труднощів. Специфіка саме цього прикладу полягає в тому, що обробка документа чисто засобами бібліотеки PHPOffice/PHPWord не дозволяє отримати необхідні можливості, а послідовне читання файлу просто неможливо. В наведеному документі всі його елементи (слова, абзаци, формули, малюнки, елементи написання) описуються серіями тегів, причому деякі можуть бути представлені послідовністю вкладених один в одного об'єктів.
Якщо взяти приклад документа (*.docx) з таблицями, ситуація зовсім не розв'язувана при послідовній обробці файлу. Потрібно як мінімум два проходи по тілу документа, якщо не вдаватися зокрема, наприклад, при вкладеності таблиць один в одного.
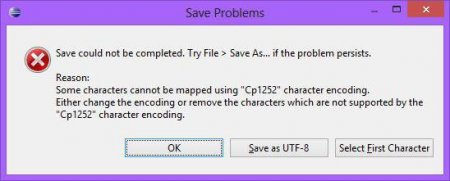 Наступний момент: кодування файлу. Далеко не завжди простий текстовий файл не створює проблем. Якщо читається текстова інформація, то наявність російських букв може створити певні труднощі (2). $cLine = iconv('UTF-8', 'CP1251', $cLine). В цьому контексті використання функції iconv() з правильним напрямком перетворення актуально не тільки щодо PHP "get file contents http://" для читання сторінки сайту, але і коли читається звичайний локальний файл. Якщо результат читання «не видно», перша справа - перевірити кодування символів.
Наступний момент: кодування файлу. Далеко не завжди простий текстовий файл не створює проблем. Якщо читається текстова інформація, то наявність російських букв може створити певні труднощі (2). $cLine = iconv('UTF-8', 'CP1251', $cLine). В цьому контексті використання функції iconv() з правильним напрямком перетворення актуально не тільки щодо PHP "get file contents http://" для читання сторінки сайту, але і коли читається звичайний локальний файл. Якщо результат читання «не видно», перша справа - перевірити кодування символів.
Синтаксис і приклад використання
Синтаксис:
Зазвичай використовується більш простий варіант file get content PHP:
Опції і параметри контексту
Слід мати на увазі, що застосування параметра $context відкриває великі можливості.
Масова обробка сторінок
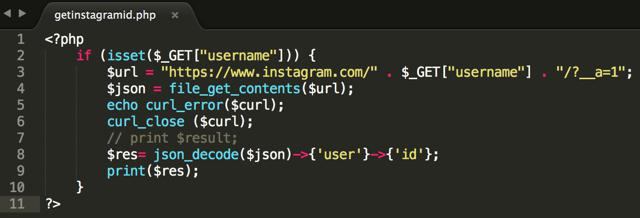
Замість конкретного адреси URL параметр $filename може бути представлений ім'ям змінної. Це дає можливість аналізувати вміст сайтів в автоматичному програмованому режимі, дізнаватися імена сторінок, визначати посилання, отримувати потрібну інформацію.
Читання текстових файлів
Проблем немає, який саме файл читати. У наступному, складному варіанті конструкція get file contents php - приклад того, що "вордівському" файл можна прочитати без проблем:
Якщо взяти приклад документа (*.docx) з таблицями, ситуація зовсім не розв'язувана при послідовній обробці файлу. Потрібно як мінімум два проходи по тілу документа, якщо не вдаватися зокрема, наприклад, при вкладеності таблиць один в одного.
Проблеми кодування і спецсимволов
Якщо читання складних файлів не викликає проблем, то проблеми викликає робота з простими файлами. Спочатку слід прийняти за аксіому: конструкція file get content PHP читає правильно. Навіть якщо не використовувати ті чи інші параметри, найпростіший варіант її застосування завжди спрацює як треба. Труднощі викликають кутові дужки і кодування файлу. Слід відрізняти роботу всередині алгоритму від відображення результату у вікні браузера. На малюнку з прикладом вордівского файлу рядок (1) - $cLine = scChangeLTGT($cLine) - викликає функцію перетворення пари кутових дужок у спецсимволи « » інакше просто прочитаний файл не завжди можна відобразити у вікні браузера. Як писати цю функцію - не суть важливо, але істотно не забувати про те, що прочитана інформація може містити теги XML і HTML, і це вимагає особливої уваги.