Вернуться назад
Распечатать
Кодування ASCII. Таблиця кодування ASCII
Під кодуванням інформації у комп'ютері розуміється процес її перетворення у форму, що дозволяє організувати більш зручну передачу, зберігання або автоматичну переробку цих даних. З цією метою використовуються різні таблиці. Кодування ASCII — це перша система, розроблена в Сполучених Штатах для роботи з англомовним текстом, яка отримала згодом поширення у всьому світі. Її опису, особливостей, властивостей і подальшого використання присвячена стаття, подана нижче. 
До числа особливостей кодування ASCII можна зарахувати і уявлення 10 цифр - «0»-«9». У другій системі числення вони починаються з 00112 а закінчуються 2-ми значеннями чисел. Так, 0101 2 еквівалентно десятичному числа п'ять, тому символ «5» записується як 001101012. Спираючись на сказане, можна легко перетворити двійково-десяткові числа в рядок в кодуванні ASCII допомогою додавання зліва бітової послідовності 00112 до кожного полубайту.
Так, виникла необхідність створення універсальної кодування тексту, розробкою якої при співпраці з багатьма лідерами світової IT-індустрії зайнявся консорціум Unicode. Його фахівцями була створена система UTF 32. В ній для кодування 1 символу виділялося 32 біта, складових 4 байта інформації. Головним недоліком було різке збільшення об'єму необхідної пам'яті в цілих 4 рази, що тягло за собою безліч проблем. У той же час для більшості країн з офіційними мовами, що належать до індоєвропейської групи, кількість знаків, рівне 2 32 є більш ніж надлишковим. В результаті подальшої роботи фахівців з консорціуму "Юнікод" з'явилася кодування UTF-16. Вона стала тим варіантом перетворення символьної інформації, яка влаштувала всіх як по обсязі необхідної пам'яті, так і за кількістю кодованих символів. Саме тому UTF-16 була прийнята за замовчуванням і в ній для одного знака потрібно зарезервувати 2 байти. Навіть ця досить просунута і вдала версія "Юнікод" мала деякі недоліки, і після переходу від розширеної версії ASCII до UTF-16 збільшувала вагу документа в два рази. У зв'язку з цим було вирішено використовувати кодування змінної довжини UTF-8. У такому випадку кожен символ вихідного тексту кодується послідовністю довжиною від 1 до 6 байт.
В різних операційних системах перевага віддається різним кодуванням. Щоб мати можливість читати і редагувати тексти, набрані в інший кодуванні, застосовуються програми перекодування російського тексту. Деякі текстові редактори містять вбудовані перекодировщики і дозволяють читати текст незалежно від кодування. Тепер ви знаєте, скільки символів у кодуванні ASCII і, як і чому вона була розроблена. Звичайно, сьогодні найбільшого поширення в світі отримав стандарт Юнікод. Однак не можна забувати, що він створений на базі ASCII, тому слід належним чином оцінювати внесок його розробників у сферу IT.
Тепер ви знаєте, скільки символів у кодуванні ASCII і, як і чому вона була розроблена. Звичайно, сьогодні найбільшого поширення в світі отримав стандарт Юнікод. Однак не можна забувати, що він створений на базі ASCII, тому слід належним чином оцінювати внесок його розробників у сферу IT.
Відображення і зберігання інформації в ЕОМ
Символи на моніторі комп'ютера або того чи іншого мобільного цифрового гаджета формуються на основі наборів векторних форм всіляких знаків коду, що дозволяє знайти серед них той символ, який потрібно вставити в потрібне місце. Він являє собою послідовність біт. Таким чином, кожному символу повинен відповідати набір нулів і одиниць, які стоять у певному, унікальному порядку.Як все починалося
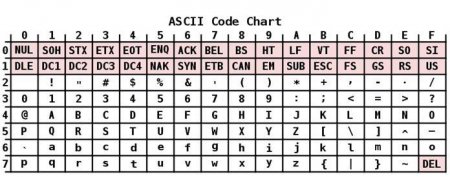
Історично склалося так, що перші ЕОМ були англомовними. Для кодування символьної інформації в них було досить використовувати всього лише 7 біт пам'яті, тоді як для цієї мети виділявся 1 байт, що складається з 8 бітів. Кількість знаків, зрозумілих комп'ютером в такому разі, було одно 128. У число таких символів входили англійський алфавіт з його знаками пунктуації, цифри і деякі спеціальні символи. Англомовна семибитная кодування з відповідною таблицею (кодовою сторінкою), розроблена в 1963 році, була названа American Standard Code for Information Interchange. Зазвичай для її позначення використовувалася і використовується й донині абревіатура «Кодування ASCII.Перехід до багатомовності
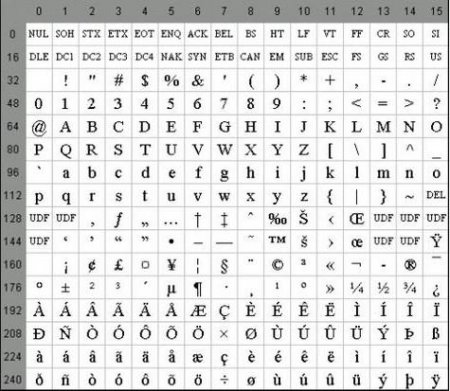
З часом комп'ютери стали широко використовуватися і в неангломовних країнах. У зв'язку з цим з'явилася потреба в кодуваннях, що дозволяють використовувати національні мови. Було вирішено не винаходити велосипед, і взяти за основу ASCII. Таблиця кодування в новій редакції значно розширилася. Використання 8-го біта дозволило переводити на комп'ютерний мову вже 256 символів.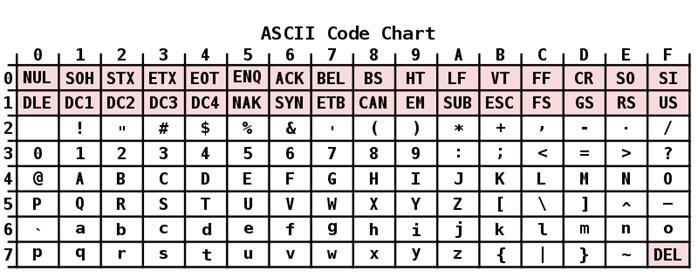
Опис
Кодування ASCII має таблицю, яка ділиться на 2 частини. Загальноприйнятим міжнародним стандартом прийнято вважати лише її першу половину. У неї входять: Символи з порядковими номерами від 0 до 31 кодовані послідовностями від 00000000 до 00011111. Вони відведені для керуючих символів, які керують процесом виведення тексту на екран або принтер, подачею звукового сигналу і т. п. Символи з NN у таблиці від 32 до 127 кодовані послідовностями від 00100000 до 01111111 складають стандартну частину таблиці. В їх число входять пробіл (N 32), літери латинського алфавіту (великі та малі), десятизначні цифри від 0 до 9 знаки пунктуації, дужки різного накреслення і інші символи. Символи з порядковими номерами від 128 до 255 що кодуються послідовностями від 10000000 до 11111111. До їх числа включені букви національних алфавітів, відмінні від латинського. Саме ця альтернативна частина таблиці кодування ASCII використовується для перетворення в комп'ютерну форму російських символів.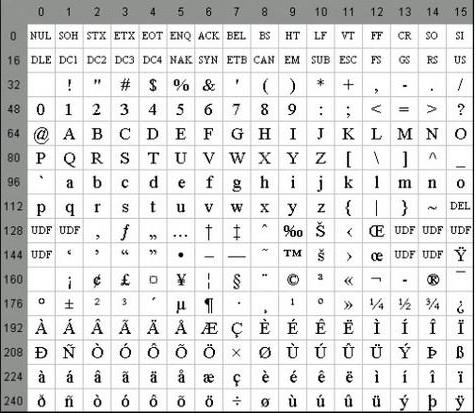
Деякі властивості
До особливостей кодування ASCII відноситься відміну літер «A» - «Z» нижнього і верхнього регістрів тільки одним бітом. Ця обставина значно спрощує перетворення регістра, а також його перевірку на належність до заданого діапазону значень. Крім того, всі літери в системае кодування ASCII представляються власними порядковими номерами в алфавіті, які записані 5 цифрами в двійковій системі числення, перед якими для літер нижнього регістру варто 011 2 , а верхнього — 010 2 .До числа особливостей кодування ASCII можна зарахувати і уявлення 10 цифр - «0»-«9». У другій системі числення вони починаються з 00112 а закінчуються 2-ми значеннями чисел. Так, 0101 2 еквівалентно десятичному числа п'ять, тому символ «5» записується як 001101012. Спираючись на сказане, можна легко перетворити двійково-десяткові числа в рядок в кодуванні ASCII допомогою додавання зліва бітової послідовності 00112 до кожного полубайту.

"Юнікод"
Як відомо, для відображення текстів на мовах групи південно-східної Азії потрібні тисячі знаків. Така їх кількість ніяк не описується в одному байті інформації, тому навіть розширені версії ASCII вже не могли задовольняти зростаючі потреби користувачів з різних країн.Так, виникла необхідність створення універсальної кодування тексту, розробкою якої при співпраці з багатьма лідерами світової IT-індустрії зайнявся консорціум Unicode. Його фахівцями була створена система UTF 32. В ній для кодування 1 символу виділялося 32 біта, складових 4 байта інформації. Головним недоліком було різке збільшення об'єму необхідної пам'яті в цілих 4 рази, що тягло за собою безліч проблем. У той же час для більшості країн з офіційними мовами, що належать до індоєвропейської групи, кількість знаків, рівне 2 32 є більш ніж надлишковим. В результаті подальшої роботи фахівців з консорціуму "Юнікод" з'явилася кодування UTF-16. Вона стала тим варіантом перетворення символьної інформації, яка влаштувала всіх як по обсязі необхідної пам'яті, так і за кількістю кодованих символів. Саме тому UTF-16 була прийнята за замовчуванням і в ній для одного знака потрібно зарезервувати 2 байти. Навіть ця досить просунута і вдала версія "Юнікод" мала деякі недоліки, і після переходу від розширеної версії ASCII до UTF-16 збільшувала вагу документа в два рази. У зв'язку з цим було вирішено використовувати кодування змінної довжини UTF-8. У такому випадку кожен символ вихідного тексту кодується послідовністю довжиною від 1 до 6 байт.

Зв'язок з American standard code for information interchange
Всі знаки латинського алфавіту в UTF-8 змінної довжини кодуються в 1 байт, як в системі кодування ASCII. Особливістю ЮТФ-8 є те, що в разі тексту на латиниці без використання інших символів, навіть програми, які не розуміють "Юнікод", все одно дозволять його прочитати. Іншими словами, базова частина кодування тексту ASCII просто переходить в склад нової UTF змінної довжини. Кириличні символи в ЮТФ-8 займають 2 байти, а, наприклад, грузинські — 3 байти. Створенням UTF-16 і 8 була вирішена основна проблема створення єдиного кодового простору в шрифтах. З тих пір виробникам шрифтів залишається тільки заповнити таблицю векторними формами символів тексту виходячи зі своїх потреб.В різних операційних системах перевага віддається різним кодуванням. Щоб мати можливість читати і редагувати тексти, набрані в інший кодуванні, застосовуються програми перекодування російського тексту. Деякі текстові редактори містять вбудовані перекодировщики і дозволяють читати текст незалежно від кодування.
