Вернуться назад
Распечатать
Видалення дублікатів MySQL distinct
Якщо б семантична організація інформації знайшла своє втілення в дійсності, то область застосування конструкції MySQL distinct моментально б самоліквідувалася. Сучасні бази даних побудовані в рамках реляційних відносин між даними, тому завдання видалення дублікатів записів актуальна.  Поява однакових рядків, як правило, не є проблемою, яку неможливо вирішити, але уникнути дублювання вмісту полів таблиць практично нереально в багатьох випадках.
Поява однакових рядків, як правило, не є проблемою, яку неможливо вирішити, але уникнути дублювання вмісту полів таблиць практично нереально в багатьох випадках.
Наприклад, схема штатного розпису буде виходити на таблицю даних про співробітників по конкретному полю. Таблиця штатного розкладу містить тільки те, що до неї відноситься в контексті конкретного підприємства, а список співробітників містить тільки особисті дані персоналу. При такому варіанті даних MySQL distinct буде працювати на запиті до обох таблиць, який з'єднує штатний розклад з співробітниками.
В ідеалі всі однакові слова розміщуються в різних таблицях і їм відповідає унікальний ключ. Наприклад, список всіх вулиць, прізвищ, імен, по батькові. В таблиці співробітників первинні схеми зливаються в потрібному варіанті подання, а до таблиці штатного розкладу підключається не список співробітників, а запит до неї і тим, які з нею пов'язані.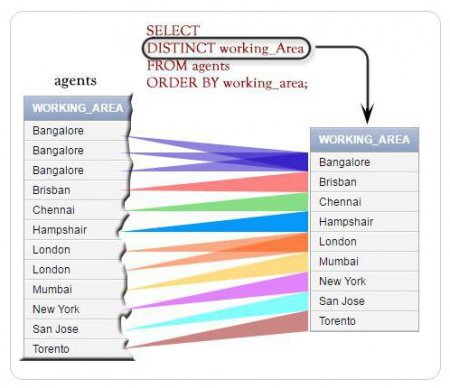 Чим більш систематизована інформація, тим більш актуально використання MySQL distinct. За правильну організацію даних доводиться «платити» - при об'єднанні таблиць загальна кількість рядків вибірки збільшується пропорційно числу рядків у кожній таблиці. Це абстрактний приклад, зазвичай розробник не деталізує інформацію до такої міри. Застосування MySQL distinct вирішує цю проблему: виберіть потрібні записи. Може стояти завдання розбору абзаців на пропозиції, пропозицій на фрази, а фраз слова. У цьому випадку без словника не обійтися, а до нього доведеться зробити словнички спряжений, закінчень і інших елементів синтаксису мови.
Чим більш систематизована інформація, тим більш актуально використання MySQL distinct. За правильну організацію даних доводиться «платити» - при об'єднанні таблиць загальна кількість рядків вибірки збільшується пропорційно числу рядків у кожній таблиці. Це абстрактний приклад, зазвичай розробник не деталізує інформацію до такої міри. Застосування MySQL distinct вирішує цю проблему: виберіть потрібні записи. Може стояти завдання розбору абзаців на пропозиції, пропозицій на фрази, а фраз слова. У цьому випадку без словника не обійтися, а до нього доведеться зробити словнички спряжений, закінчень і інших елементів синтаксису мови. 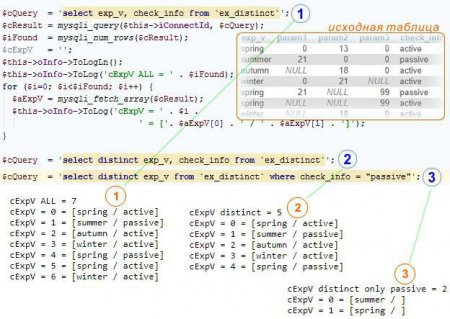 Функціональні можливості оператора вибірки тільки унікальних записів задовольняють будь-яким структурам даних. Можна використовувати запит у запиті, групувати і сортувати дані перед відбором. Проте завжди краще максимально спрощувати роботу з базою даних. Використання MySQL distinct по одному полю завжди краще, ніж робота відразу з кількох.
Функціональні можливості оператора вибірки тільки унікальних записів задовольняють будь-яким структурам даних. Можна використовувати запит у запиті, групувати і сортувати дані перед відбором. Проте завжди краще максимально спрощувати роботу з базою даних. Використання MySQL distinct по одному полю завжди краще, ніж робота відразу з кількох. 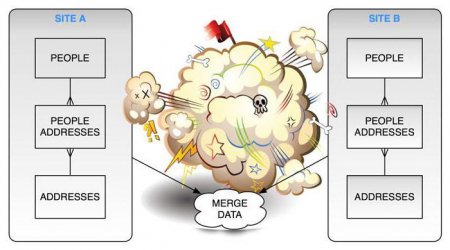 Особливо важливо уважно складати запити, які об'єднують декілька таблиць. Будь-яке об'єднання даних у реляційних базах, до того як почнуть функціонувати конструкції where і join призводить до великих обсягів даних. Орієнтація в них вимагає уважності і акуратності від розробника.
Особливо важливо уважно складати запити, які об'єднують декілька таблиць. Будь-яке об'єднання даних у реляційних базах, до того як почнуть функціонувати конструкції where і join призводить до великих обсягів даних. Орієнтація в них вимагає уважності і акуратності від розробника.

Організація бази даних
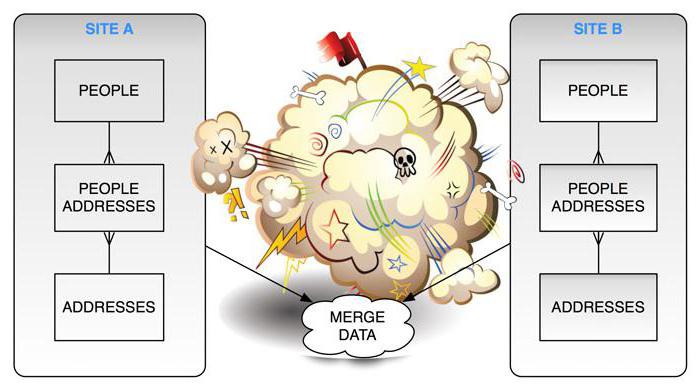
Вважається, що «правильна» база даних містить унікальні таблиці, а кожна з них містить унікальні поля. Допускається наявність однакового вмісту в полях різних таблиць тільки в тому випадку, коли вони є ключовими і за ним здійснюється логічний зв'язок даних.Наприклад, схема штатного розпису буде виходити на таблицю даних про співробітників по конкретному полю. Таблиця штатного розкладу містить тільки те, що до неї відноситься в контексті конкретного підприємства, а список співробітників містить тільки особисті дані персоналу. При такому варіанті даних MySQL distinct буде працювати на запиті до обох таблиць, який з'єднує штатний розклад з співробітниками.
Унікальність таблиць і полів
При взаємодії таблиці штатного розкладу і списку співробітників для кожного рядка першої таблиці є спеціальне місце у другий. Друга таблиця може містити однакові прізвища, імена, по батькові людей, адреси проживання в місті також можуть містити ідентичні вулиці. Номери будинків і квартир можуть не мати особливого значення (вони не займають багато місця).В ідеалі всі однакові слова розміщуються в різних таблицях і їм відповідає унікальний ключ. Наприклад, список всіх вулиць, прізвищ, імен, по батькові. В таблиці співробітників первинні схеми зливаються в потрібному варіанті подання, а до таблиці штатного розкладу підключається не список співробітників, а запит до неї і тим, які з нею пов'язані.
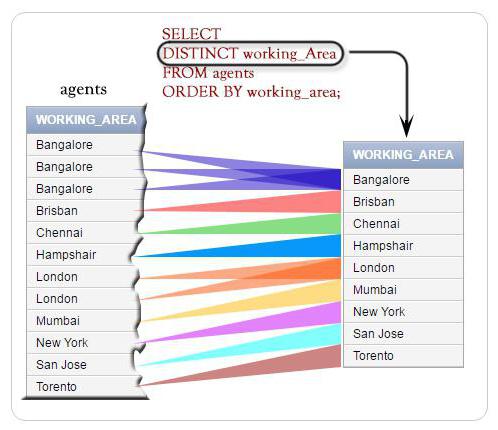
Приклад вибірки MySQL query "select distinct "
В таблиці є запис, в яких чотири пори року і два стани запису: активна і пасивна. Приклади вибірки: всіх записів; тільки унікальних; унікальних в межах умови. Вони можуть бути такими, як зазначено на зображення в статті.